Tech Blog
The latest technical blogs from the Triton Consulting team.
All the content and authors from our Confessions of a Db2 Geek blog can be found here.
You can also access additional educational content in our Resources section.
Filter by: Author
- All
-
Rob Gould
-
Maryam Asghari
-
Mark Gillis
-
John Perks
-
James Gill
-
Iqbal Goralwalla
-
Gareth Copplestone-Jones
-
Damir Wilder
-
Carol Davis-Mann
-
Alan Roberts
Filter by: Tag
-
Database Services
-
Julian Stuhler
-
Mainframe
-
Mainframe Cost Management
-
Mark Gillis
-
Modernisation Services
-
Pacemaker
-
RemoteDBA
-
REST API
-
Rob Gould
-
Tech Tips
-
Events
-
Db2 13
-
Jenkins
-
Alan Roberts
-
Maryam Asghari
-
OpenShift
-
John Perks
-
LDUG
-
Change Data Capture
-
CDC
-
Robert Philo
-
Expert on Demand
-
UK Db2 User Group
-
SDUG
-
Db2 pureScale
-
Cloud
-
Consultancy on Demand
-
Damir Wilder
-
Database Availability
-
Database Management
-
Db2
-
Db2 11.5
-
Db2 12
-
Db2 Consultancy
-
Db2 Health Check
-
Db2 Locking
-
Db2 LUW
-
Ansible
-
Db2 Support
-
Db2 z/OS
-
DevOps
-
Gareth Copplestone-Jones
-
HADR
-
IBM
-
IBM Champion
-
IDUG
-
Infrastructure Services
-
Iqbal Goralwalla
-
James Gill
Sort by: Most recent





Single Node OpenShift – Up and Running

Lagging Behind or How to Find What Your Backup Image Doesn’t Contain

Managing DDF Workloads in Db2 for z/OS

Ansible Collection for Db2 for z/OS
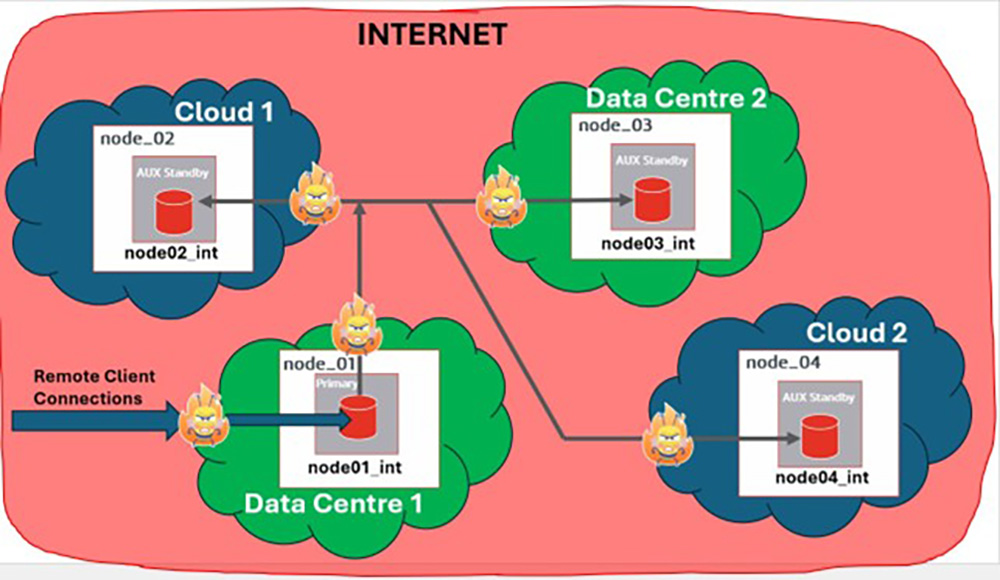
Using TLS in Hybrid HADR Clusters

AI Query Optimization - enabling and monitoring the new feature

Db2 Optimizer Version

User IDs in Db2
