
In this exercise we shall look at several different methods of tuning a poorly performing SQL query.
The Problem
The Original SQL Query
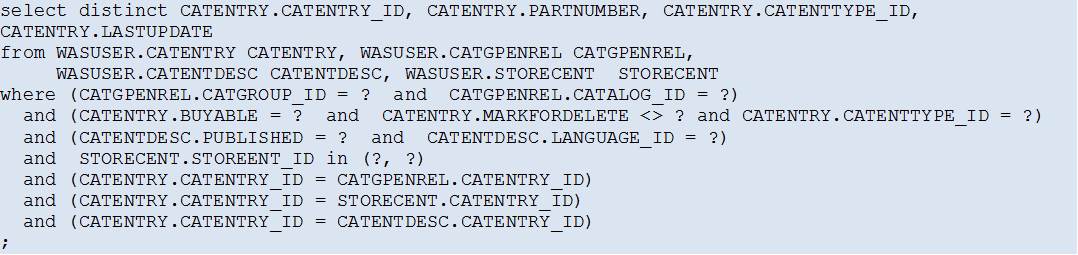
The Original Access Path

So, where is the problem?
Looking at the Access Path chosen by the DB2 Optimizer, all looks well – all tables are either accessed via indexes, or not at all (index-only access), which is what we usually strive to achieve.
The estimated cost for the whole query is also not very high (1726.3 timerons).
However, looking at the actual query performance data:

it turns out that for each statement execution all rows from the CATENTRY table are read, regardless of the index access (6):
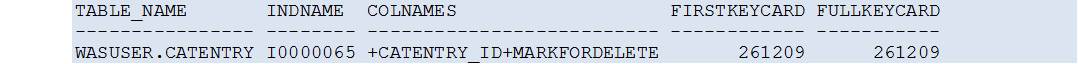
Why is that?
The reason can be found by taking a closer look at the index used.
Even though the index cardinality seems to be excellent (both FIRSTKEYCARD and FULLKEYCARD are equal to the table cardinality!), this in itself does not help at all because the row filtering is not done on the first column in the index, CATENTRY_ID (this column is only used later in the query processing, to join the table data with the data from other tables).
On the other hand, the second index column which is used for the row filtering, via the predicate:

has a very poor cardinality (which is not immediately visible from looking at the index data in the system catalogue, SYSCAT.INDEXES, as shown above):

All rows in the table CATENTRY contain only one value (0) in the column MARKFORDELETE!
This is the main reason why the table CATENTRY is so heavily read – whenever the query is executed with the parameter value :MARKFORDELETE <> 0, all rows from the table CATENTRY will qualify and must be read into the memory (for later joining with other tables, according to the actual Access Path).
How to fix this?
After looking at the data distribution for all columns that are used in the query predicates (and so eligible for the row filtering), one candidate clearly stands out:

While all other filtering columns have a very low cardinality (of one or very few distinct values), only this column possesses a (somewhat) acceptable data distribution.
So, in order to improve this query’s performance, the DB2 Optimizer should be persuaded to first use an index on the column CATGPENREL.CATGROUP_ID, which has the best row filtering potential, to find all matching rows (or index entries for index-only access) and only then to join the selected rows to the table WASUSER.CATENTRY.
One such index already exists and is the Primary Key for the table WASUSER.CATGPENREL:

The Solution(s)
1)Rewrite the query
Sometimes it is possible to rewrite the query in such a way that the DB2 Optimizer decides to use the desired index.
In our case, slightly altering the predicate on the column CATENTRY.MARKFORDELETE did the trick:
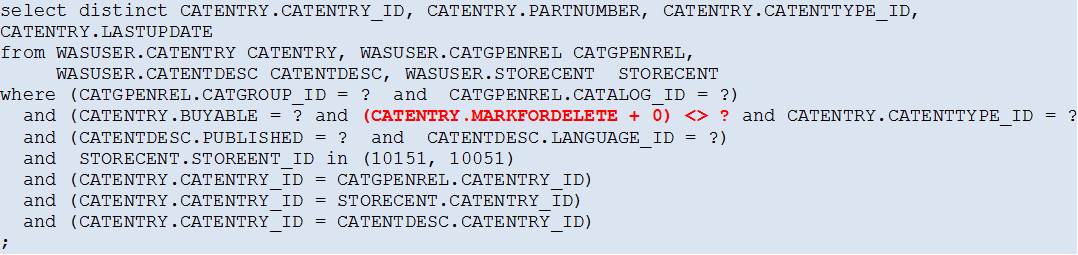
The Access Path now looks much better (and the Estimated Cardinality more realistic).
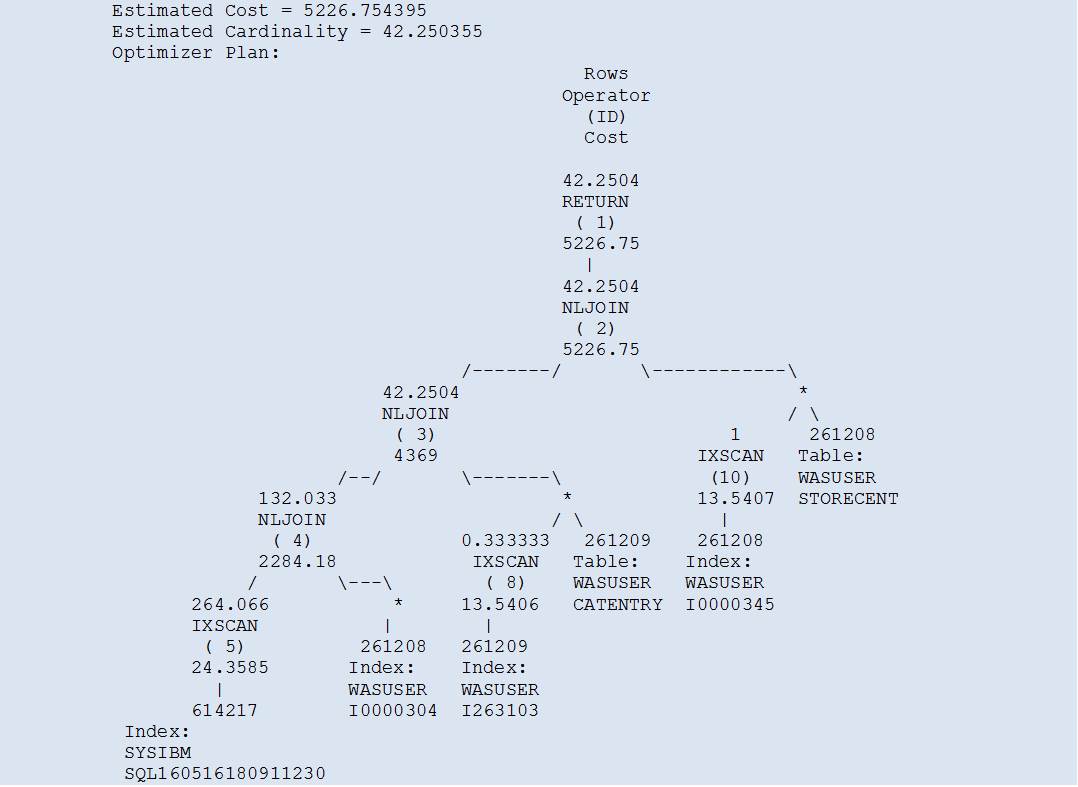
Even though the Estimated Query Cost is higher than before, the processing starts with the Primary Key for the table WASUSER.CATGPENREL, which is exactly what we wanted to achieve.
2) Using the Selectivity
Another option that also requires a slight query rewrite is to use the Selectivity Clause in the SQL statement.
A different Selectivity Clause can be added to each individual predicate in the query, specifying the selectivity for that particular predicate which is then used by the DB2 Optimizer to calculate the Access Path.
To enable this feature, first a DB2 registry variable must be set:

(instance restart is not required if the ”–immediate” parameter is used)
After enabling the Selectivity Clause, the query is rewritten as:
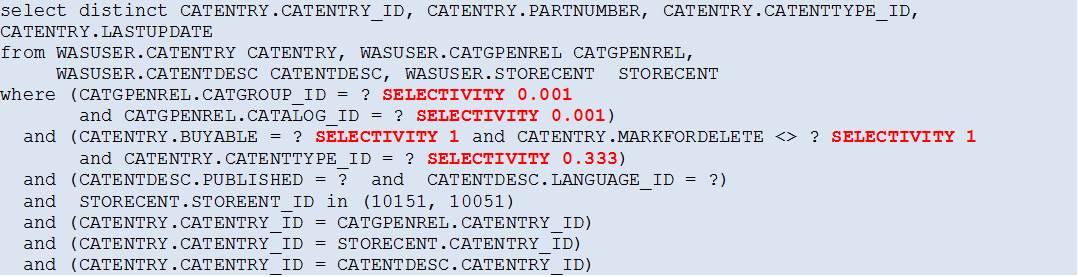
The resulting Access Path is equal to that of solution 1).
3) Using Optimization Profiles
The last option discussed here is the use of the Optimization Profiles, which requires minimal changes to the application (none to the SQL statement itself).
To setup the database and the application to use the Optimization Profiles:
1. Create the optimization profile table (SYSTOOLS.OPT_PROFILE):
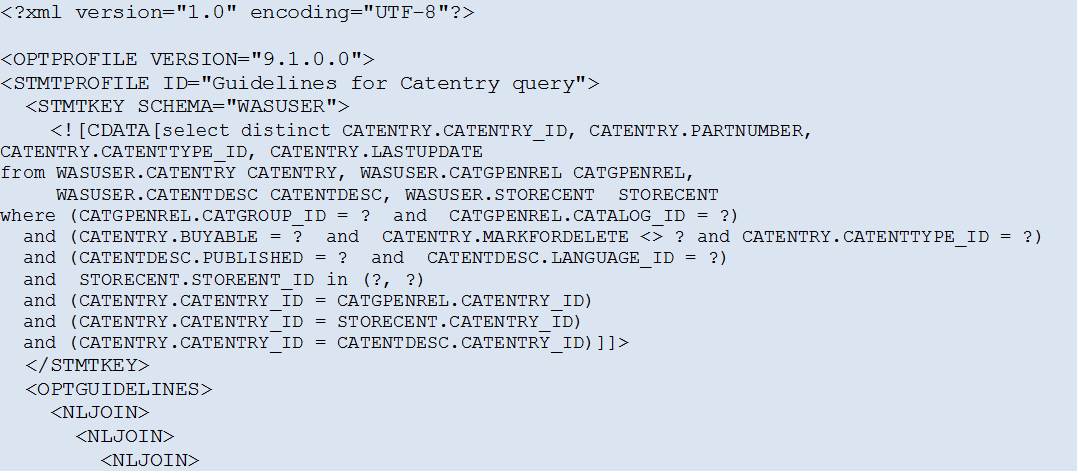
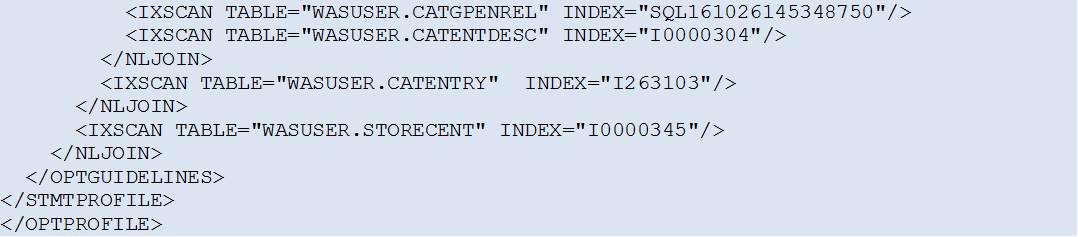
2. Create the file “OPT_PROFILE_1.XML” that will contain the Optimization Profile:
3. Create a simple textual input data file “OPT_PROFILE_1.TXT”, that contains one row:
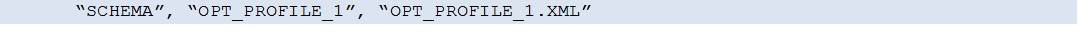
4. Import the Optimization Profile into the table SYSTOOLS.OPT_PROFILE (created in step 1):

5. Enable the use of the Optimization Profile from within the application by setting the CURRENT OPTIMIZATION PROFILE special register:
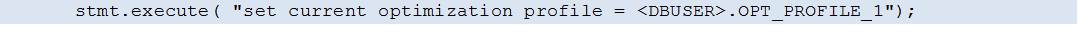
The above statement may vary, depending on the type of the application/database access method.
An exhaustive description is given in the following DeveloperWorks article:
https://www.ibm.com/developerworks/data/library/techarticle/dm-0612chen/
Once the Optimization Profile has been properly setup and the application indicates that it wants to use it, the DB2 Optimizer will use the supplied hints for all matching SQL statements.
In our example, the resulting Access Plan is equal to that of solution 1).
Further information on Optimization Profiles can be found in the DB2 Knowledge Center:
Conclusion
The SQL query tuning solutions presented in this article are not exhaustive, there are other means and methods of tuning SQL queries which were not discussed here (statistical views, REOPT bind option, distribution statistics, MQTs, etc.).
The purpose of this article was to show several successful methods of tuning a one particular query from a real life situation.