

Introduction
TSA/HADR is a combination of (IBM’s) technologies that facilitates high availability and disaster recovery in a world of DB2 (“High Availability and Disaster Recovery” – that is what HADR stands for). Tivoli System Automation (for Multiplatforms) is the long for TSA(MP).
HADR on its own provides mainly Disaster Recovery, by maintaining more than one synchronised copy of a DB2 database. Should a primary DB2 server fail and render its database useless, there is always one database copy (“standby database”) that can be utilised instead (in later releases there can be up to three copies). The process of switching from a primary database to a standby database, called failover, must be initiated manually by the DBA, which is not a problem, unless the failure occurs when DBA is not online (think overnight, weekend, public holiday..). In such cases a prolonged database downtime is the usual result.
This is where TSA(MP) comes into play: it actively monitors the health of the databases and their host servers and in any kind of primary server/database failure it automatically performs the failover to the standby server, thus keeping the database downtime to a minimum, without any need for a DBA intervention (to the best of my knowledge, TSA(MP) monitors, automates and keeps alive other non-DB2 things too, but since this is a DB2 related article, I shall not go beyond that frontier).
Everything so far refers to the server side and what happens to the database itself.
But what about the client side?
What about the clients that are connected to a database and are actively executing a task, a batch job, or something else equally important, at the time of a database failure, when a failover occurs (be it manually or automatically initiated one) and the active database is moved to another server?
Do the clients also automatically “survive” the failover, and if they do, how?
Or do the clients have to explicitly reconnect to the database and only then resume their interrupted jobs?
In this four-part series I will try to explore how different configurations of a TSA/HADR cluster influence the active client connections during a cluster failover.
TSA/HADR cluster setup
For the purposes of this exercise I will use a standard SAMPLE database deployed on two servers [1]:

[1] don’t ask about the server names, that is a company policy 🙂
The servers, or rather – SAMPLE databases – are arranged in a simple (single standby) near synchronous HADR Primary-Standby setup. This HADR pair is then configured into a single TSA cluster, whose primary purpose is the monitoring and automation of failovers between the database servers.
Let’s quickly go through the process of configuring HADR and TSA.
HADR setup
The SAMPLE database is first created on the primary server (ITCHY) and configured for HADR:
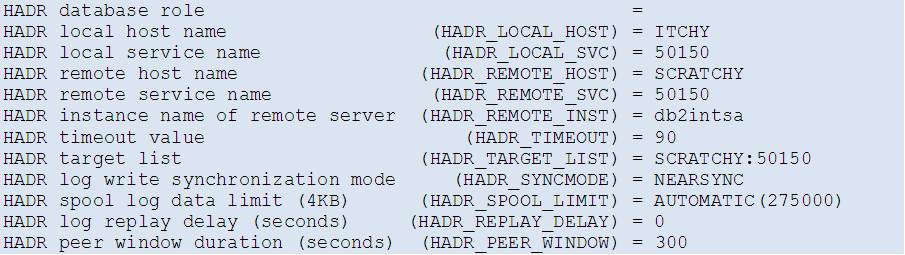
Following the HADR setup guide, the database is then backed up (offline) and restored on the standby server (SCRATCHY) and also there configured for HADR:
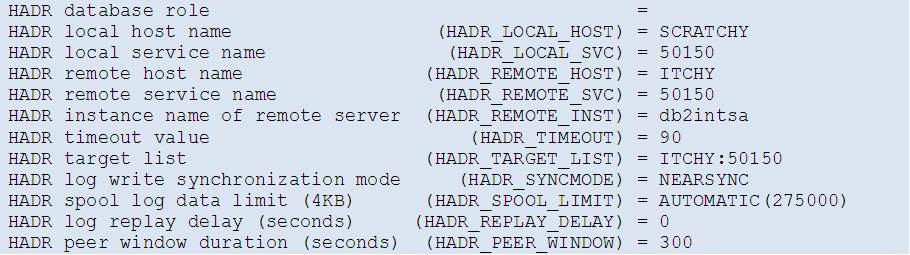
Finally, HADR is started:

The HADR role of both servers is confirmed by looking at the DB configuration (first two lines of output shown only):

TSA setup
With HADR up and running, it is time to setup the TSA cluster.
This is done using the non-interactive, or batch db2haicu setup mode:
First, the XML configuration file template that is a part of the standard DB2 installation:
is copied to a different location (on both servers) and edited for the purpose of this particular TSA cluster configuration (actual changes to the template are in red colour):
TSA_SAMPLE_primary.xml (on the primary server, ITCHY):
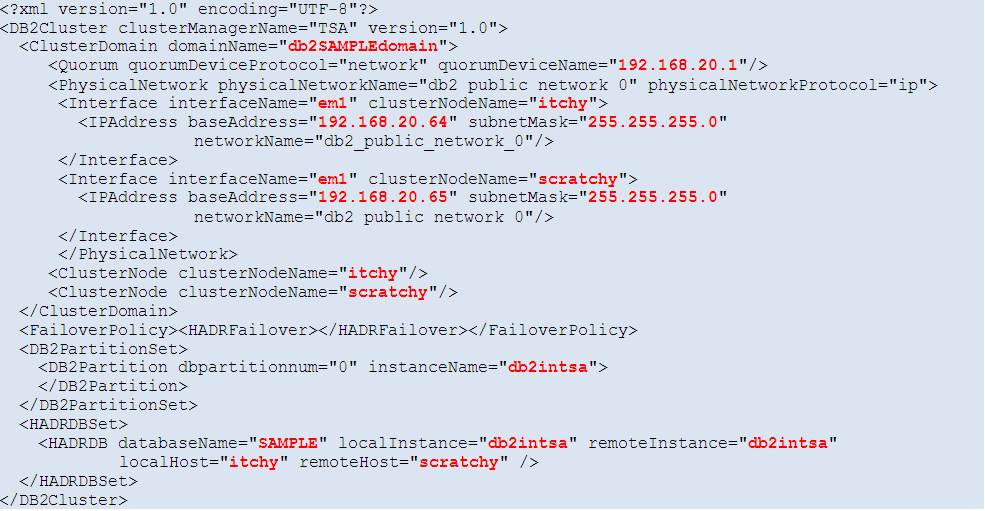
The file on the standby server (SCRATCHY), TSA_SAMPLE_standby.xml, is identical except for this one slightly different XML element:

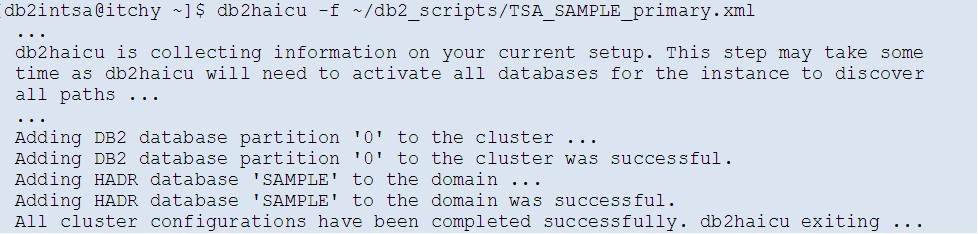
With configuration files ready, the TSA cluster is configured and started:
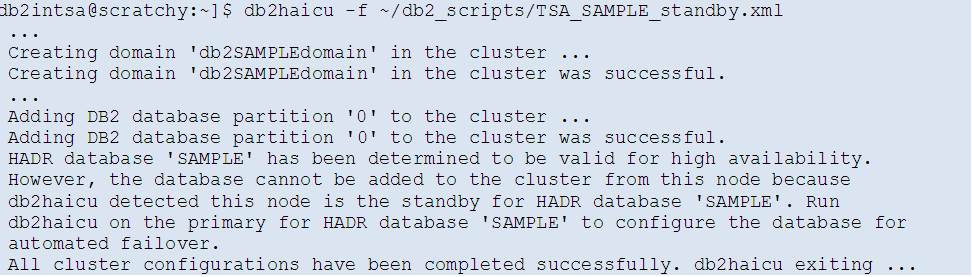
First on the Standby server (SCRATCHY):
Then on the Primary server (ITCHY):
The TSA/HADR cluster state can be checked with the ‘lssam’ command:
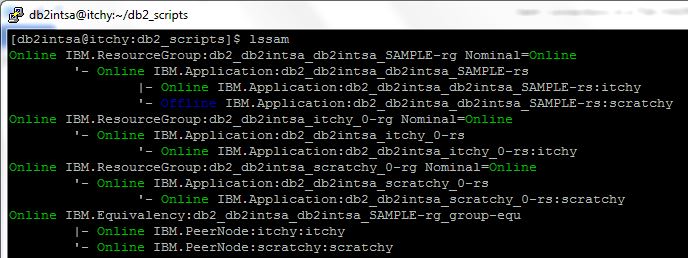
Green “Online” status for all defined TSA objects (except for the SAMPLE database on SCRATCHY, which is currently the HADR Standby and so inactive and so “Offline”) means the TSA cluster is up and running and all its monitored resources are in their desired (“Nominal=Online”) states!
Having the TSA/HADR cluster active and fully functional, it is time to setup the client and initiate a failover (and see how it affects the connected clients).
Client setup
Let’s first take a look how a client’s database access is configured and also its workload setup.
Client catalogues the remote database SAMPLE (using the local alias TSASAMPL), using the TCPIP node TSANODE, which in turn points to the current HADR primary server ITCHY (192.168.20.64):
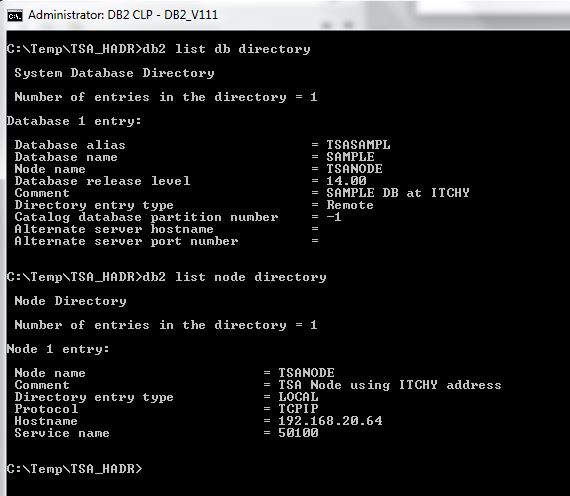
Client workload setup:
For the purposes of this exercise, it is sufficient to run a simple SQL script on the client (Windows DB2 Command line window), as it will clearly show what happens during a failover:
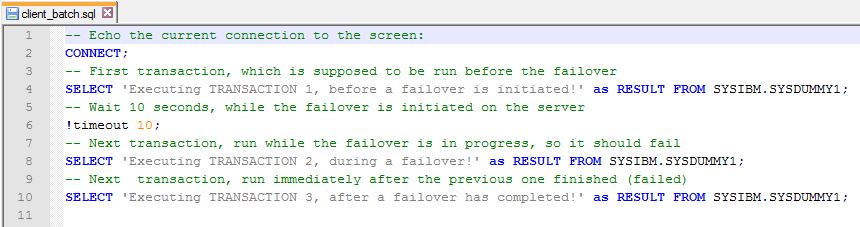
(there is actually a bit more stuff in the script which is not shown here as it is not SQL related and not the object of our investigation)
The idea is: when this script is running, sometime between the first and the second transaction (select statement) the failover is executed on the DB2 server.
The expected result is:
-first transaction should complete successfully, as it is started (and should finish) before the failover has started
-second transaction shoud fail, as it is run during the failover
-third transaction should complete, providing the client has the means to automatically reconnect to the database on the active server, following a failover.
Our focus is basically on the outcome of the third transaction!
TSA/HADR failover
With the client setup and workload outlined above, let’s see what happens to its executing batch job during a failover.
The failover is initiated manually on SCRATCHY (which is currently the Standby HADR server), by issuing a db2 TAKEOVER HADR command:
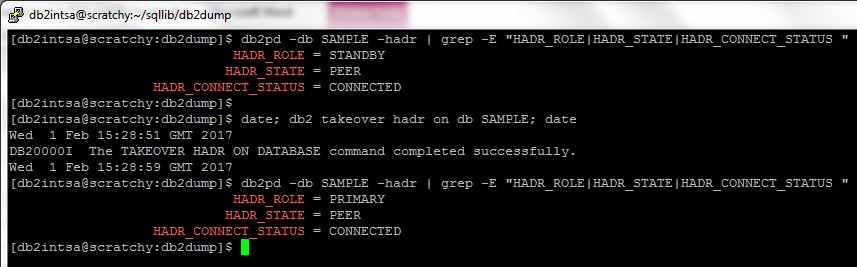
You can see that the SAMPLE database HADR_ROLE changed from STANDBY to PRIMARY on SCRATCHY, meaning this database is now active and accepting client connections (whereas the formerly active SAMPLE database on ITCHY is now inactive, on standby).
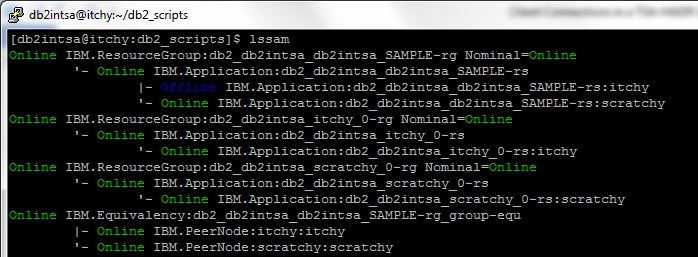
The HADR role change is also reflected in the TSA status, which now shows node SCRATCHY as Online and node ITCHY as Offline:
This is what happened on the client at the same time:
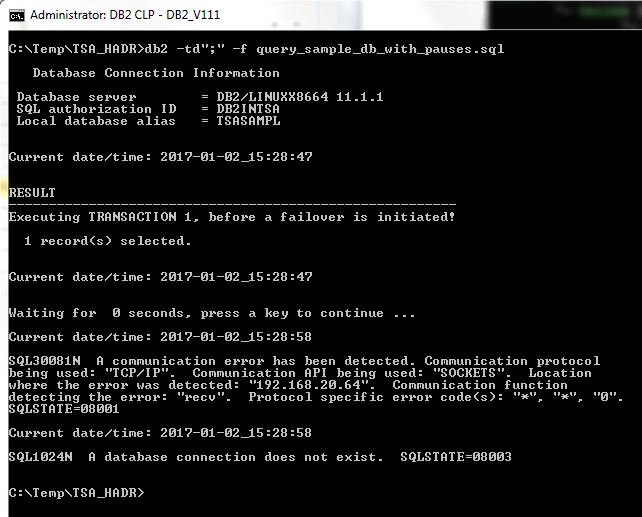
The batch job fails completely after a failover (both transactions #2 and #3 fail) – expectedly, because the database that the client is connected to (TSASAMPL) is no longer available on the configured TSANODE – it moved to the other server as shown above.
Even worse, simple reconnecting to the database and restarting the batch job on the client is not possible (since the client is not configured to access the database on the server SCRATCHY):
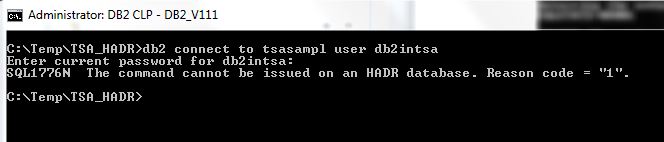
The client must be manually reconfigured before it can reconnect to the database and resume its batch job processing:

Conclusion
While this scenario is OK from the server’s side (the database was safely moved to another node in the cluster and so the downtime was avoided), it is not at all acceptable from the client’s perspective, as business continuity is not maintained in case of a TSA/HADR failover (a DBA intervention is required before the work can be resumed).
In the next parts (Part 2, Part 3, Part 4) I will show what configuration options are available to ease the pain on the client side.
You can read Part 2 of my blog here.