
Why Ingest?
INGEST is a utility introduced in DB2 V10.1 to put data, sourced via a Pipe or Flat file, into a target table or set of tables. It’s sometimes referred to as “Continuous Data Ingest (CDI)” as one of its main advertised benefits is to be able to continuously pump data in DB2 tables. I’m not convinced that this is its best selling point: Continuous Data Ingest relies on data being delivered via a pipe, and that means an area of shared memory.
But it’s the INGEST commands ability to do more than just Insert or Replace data that I think is it’s real selling point. Instead of spending time and money on ETL tools, INGEST can leverage existing DB2 features to quickly and reliably take data extracted from another system; apply it to the correct data stores using embedded metadata, transform or enrich the content and do to so with a single command. It is also highly efficient and can add, remove and modify data with very little impact to ongoing activity in the target database.
There are already some decent comparisons out there between IMPORT, LOAD and INGEST (try
but INGEST offers options that these features do not. They come with gotchas, of course, so I’ll go over some of those in a subsequent blog, but I’ll begin with some practical examples based on a Proof of Concept.
Extra data
The data that is exported and provided to INGEST for processing can include some extra values that do not necessarily need to be loaded into your target tables, but can help our processing. Obviously IMPORT and LOAD can also accept more data than is needed and pick out the columns, or delimited fields, that are needed in the target table. But INGEST can be defined to perform actions based on the data that is being fed to it. An INGEST command that includes the code fragment below will examine the incoming data and perform different actions based on the data it contains

In other words, you can pass metadata to the utility to determine what actions need to be performed for that row of incoming data.
Merge, Update and Delete
INGEST can also exercise a greater range of operations than either LOAD or IMPORT. You can define a data stream to include metadata and make the syntax intelligent enough to determine what do to with each row of data. Building on the syntax above (i.e. using data embedded in the data stream to define actions within the INGEST command) you might be able to use a single command to handle any data update:
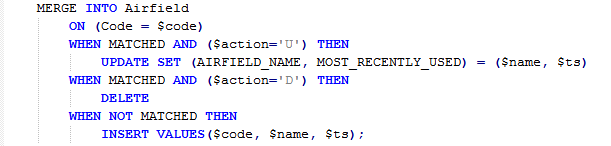
Why is this useful?
Here’s a scenario then: we have a table called Airfield in a database on instance DB2_01 and we want to have the same data available in a copy of this database on another instance, DB2_02, with minimal interference to either system. We want a simple mechanism that can act on a single data stream to keep DB2_02 up to date. We don’t have the time, manpower or skills to use SQL or Q Replication or Third Party ETL tools.
INGEST can come to our rescue:
Define a set of triggers on the source table, to put Update, Insert and Delete data into a staging table. (The example below shows an Update trigger but Insert and Delete triggers would also be defined, with very similar syntax, to trap all data changes). Notice that the data written to the Airfield_INGEST table includes the user, the current timestamp and an ‘action code’ indicating that this is an Update. The Insert trigger would include an Action Code of ‘I’ and the Delete trigger an Action Code of ‘D’
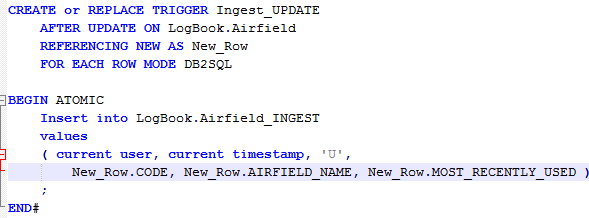
2. Whenever any alterations take place on the source system, the triggers write the data to the AIRFIELD_INGEST table (including a timestamp allows the data to be applied in the correct order). The data can then be extracted from the staging table (to a flat file in this example) and the staging table cleaned out

3. Once the file has arrived at the target server, the INGEST command can be executed. That can be scheduled or kicked off by the appearance of the flat file: something like this usually works for me, as a shell script

What’s important is that it will accept all the data, in a single stream, and determine the correct operations to perform in a single command
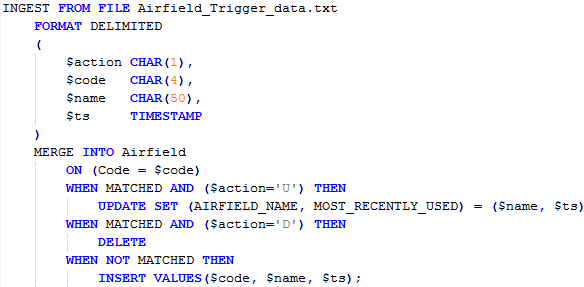
You’ll notice the MERGE command from earlier but, hopefully, you see why I coded it in this manner. The input data contains an action code that confirms which operation is required and the MERGE will apply an UPDATE, INSERT or DELETE as appropriate. Once the INGEST command has run, the updates, inserts and deletes that were run on the source system will have been applied to the target system, in the correct order and to the appropriate tables, in a single operation.
In the next blog, I’ll show some more complex operations and then some things to watch out for.