
Guest Author: Sebastian Zok
Years ago when I was a consultant I helped a customer move their DB2 system from one data centre to another data centre located in a different country. In addition, we also switched endianness which unfortunately hindered the usual backup and restore approach. Bringing over the terabyte of data wasn’t the biggest problem, but checking the referential integrity after loading the data did take several days.
Whilst attending IDUG EMEA in Rotterdam 2019, I discussed the issue with fellow DB2 consultants. I learnt that they also came across the same issues when migrating large databases between data centres or from on premise to cloud (which is effectively also a data centre move). Following my conversations I thought it would be a good idea to provide them with my old, but working approach below.
This article will explain how to speed up the execution of dependent DB2 tasks (for example: SET INTEGRITY processing) by running them in parallel.
Put some order into SET INTEGRITY processing
For a small number of tables you could run the SET INTEGRITY statements in whatever order you want, regenerating the statements after each iteration for all tables still in the check pending state and re-execute the statements till there are no check pending tables anymore. But if you want to have the SET INTEGRITY statements in the right order to begin with, you must use a little bit of cleverness.
I used an approach offered by Daniel Luksetich which I slightly altered to better suit my purpose (see https://github.com/The-DataDoctor/Db2_Scripts → SQL_Scripts/get_table_dependencies.sql).
This is nothing more than a recursive SQL statement that pulls the table dependencies within the table hierarchy out of the DB2 catalog.
When you execute this SQL statement, you will get a list of all tables (it is possible to filter the tables within SQL) from your database in order of the referential dependencies and each table will be assigned an appropriate tier level (more on this later on). Generally, the parent tables will have lower tier numbers than their child tables, and the deeper the child tables are within the RI structure the higher their tier will be. Be aware that the tables with circular references will have to be handled with special care (an example follows).
This approach will save you time as you will only need to run the SET INTEGRITY statements once and will not miss any tables that might have been added to the database but still aren’t documented.
Parallelize the unparallelizable
In my case, the simple ordered approach has been running around 40 hours and still not nearly done.
Monitoring the machine where it ran showed that it was well under it’s maximum performance capacity. Disk and CPU utilization were at 10-20%. After looking into it more closely, I found that an individual SET INTEGRITY statement couldn’t be parallelized on its own. Running a single SET INTEGRITY statement utilises a maximum of 100% of a single CPU core but not any more than that. Even if you have one SET INTEGRITY statement dealing with multiple tables it will still process one table after another and utilise only one CPU core.
So using a single SET INTEGRITY statement to process multiple tables only makes sense when you try to solve a circular reference.
To speed up the whole process you have to run multiple statements in parallel … but at the same time keep the table dependencies (trying to process a child table before its parent will result in a failure, as we all know very well)!
The Infrastructure
Having identified the problem I set about creating a solution: I wrote a Perl script “parallel.pl” capable of running multiple worker threads in parallel. Each thread executes the input commands in the order in which the commands appear in the input file.
To maintain the table dependency between the threads, all input commands contain a tier number and before any of the workers can move on to executing the commands from the next higher tier all commands from the lower tier have to be finished first. See parallel.pl in my github for more info.
Read the code or run the script without parameters to get the usage note:

SET INTEGRITY Usage Example
As the script isn’t running within a DB2 context on its own, you will need to explicitly open a connection to your database. Opening the connection as the first command within your input script (using a lower tier number than for any other subsequent commands) does the trick as this connection is then used by all threads running the rest of the commands.
The following line shows the syntax for a DB2 connect statement in tier 0, with the instruction to terminate the whole process if the command fails:

With a connection to the database in place, we are ready to move on to the tables and their dependencies.
Following is a sample table structure:

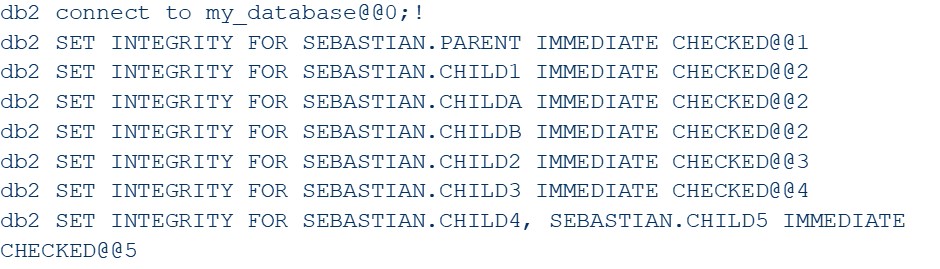
Notice that tables CHILD4 and CHILD5 have a circular reference as they reference each other. This will have to be handled in a slightly different fashion, as mentioned before.
With the above table structure the input file for the perl script could look like this (notice the increasing tier number for each next “generation” of child table(s) ):
Opinions from the DB2 Community
“We have recently used the script parallel.pl while migrating the client’s DB2 databases from the on-premise data centre to the AWS Cloud and it helped us greatly improve several migration steps: exporting the data from the local database, copying the exported data to the Cloud, loading the data into target database, running the SET INTEGRITY and the RUNSTATS commands on the target database. In some cases we were able to improve the performance six-fold (600%)!” Damir Wilder, Senior Consultant, Triton Consulting
Disclaimer
As described the approach is already some years old. Script and SQL could surely be improved but it’s running as is and time consuming is what’s executed not the stuff running it. Feel free to give the scripts a try yourself. I’m open to any questions, recommendations or feedback so please come back to me on LinkedIn if you have any.
 About Sebastian Zok: Guest Author
About Sebastian Zok: Guest Author
Favourite topics: SQL, automation/scripting, data analysis
Sebastian has been a DB2 consultant for over 10 years, starting his career at ITGAIN Consulting GmbH where he combined work with study gaining a diploma in 2007. Sebastian has predominantly worked in finance and insurance sectors from single small database up to Terabyte big data warehouse or hundreds of databases in an infrastructure.
Since 2018 Sebastian has been employed as a DB2 DBA and SQL specialist for Dirk Rossmann GmbH, one of the biggest drug store chains with over 2500 stores. He is an IBM Champion and has been a voluntary member of the IDUG European Conference Planning Committee since 2017.
When he is not sport shooting, Sebastian enjoys time with his family (married father of twins) and playing X-Wing TMG.