

In the first of these blogs (11-5-4-nebula-blu-enhancements) I was looking at one of the issues that has been around since columnar storage was introduced in v10.5: the lack of encoding for VarChar and other similar data types. This gap has now been plugged and another one that Nebula tackles is the processing associated with the Synopsis table.
Deferred Synopsis table processing
Another of the performance features of column-organized data is data skipping. This is accomplished by maintaining a Synopsis Table, which is done automatically, but which incurs a processing overhead. Basically, for every 1,048 ‘rows’ of data processed in the main table, a row is written to the synopsis table showing the start and end position for each set of values in that ‘block’. This is very efficient for massive quantities of data; not so if the columnar data is small, or being inserted in small batches. You could end up writing a row to the synopsis table for every ‘row’ (in quotes, because it isn’t a row; it’s columnar, but the row of data you supply is decomposed into columnar format and we, as users, still think of the data as being a row). There is now a new feature, available as an 11.5.4 Nebula BLU enhancement that will deal with this. Published details are here: V11.5 Column-organized table variable but there are glitches and gotchas to consider.
A registry variable DB2_COL_SYNOPSIS_SETTINGS=DEFER_FIRST_SYNOPSIS_TUPLE:YES is now available to reduce the impact on the synopsis table of processing small sets of data, by allowing Deferred Synopsis table processing.
By way of example
-
- create a Column-organized table and check contents of synopsis table (empty) and size (both base and synopsis table are 256 K)

-
- load 3 rows into base table; size is now 640 K for the base table and 1024 K for the synopsis table. There is a single row in the synopsis table

That’s clearly not very efficient but to illustrate the advantages to their full extent, you need to look at what happens around the 10,000 row threshold (NB: this is a current hard-coded threshold but may be subject to change in the future).
-
- First off; build a column-organized table with the DB2_COL_SYNOPSIS_SETTINGS not yet set but don’t yet populate with any data. Both base and synopsis table are 256K
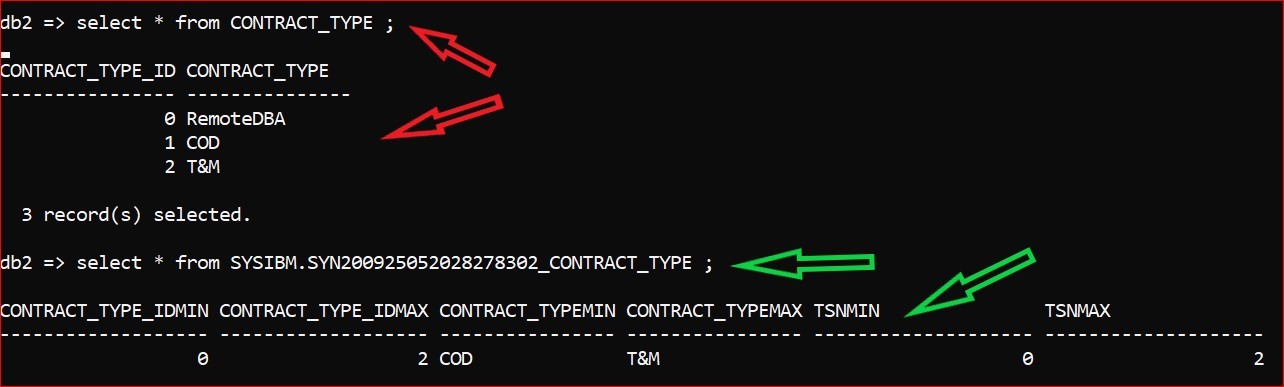
NB the previous example used a dimension table called CONTRACT_TYPE; the following examples use the fact table CONTRACT

-
- You then INSERT 9,900 rows (NB: you won’t get the benefits with LOAD. Setting the registry variable doesn’t affect data populated via LOAD). The table sizes are now as shown below, along with the contents of the Synopsis table

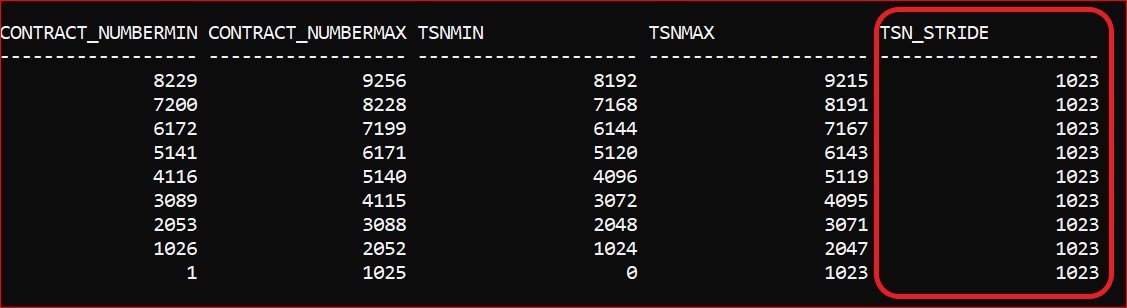
You can see that there are 9 rows (I’m still saying rows, although the synopsis table is itself column-organized) in the Synopsis table but this occupies 2,048 KB as compared to the 1,152 KB used by the base table to store 9,900 ‘rows’. I believe the term for a range of Tuple Sequence Numbers (TSN) is a ‘stride’ and you can also see here a uniform volume of TSNs for each ‘stride’ of base data.
-
- If you now set your registry variable:
db2set DB2_COL_SYNOPSIS_SETTINGS=DEFER_FIRST_SYNOPSIS_TUPLE:YES
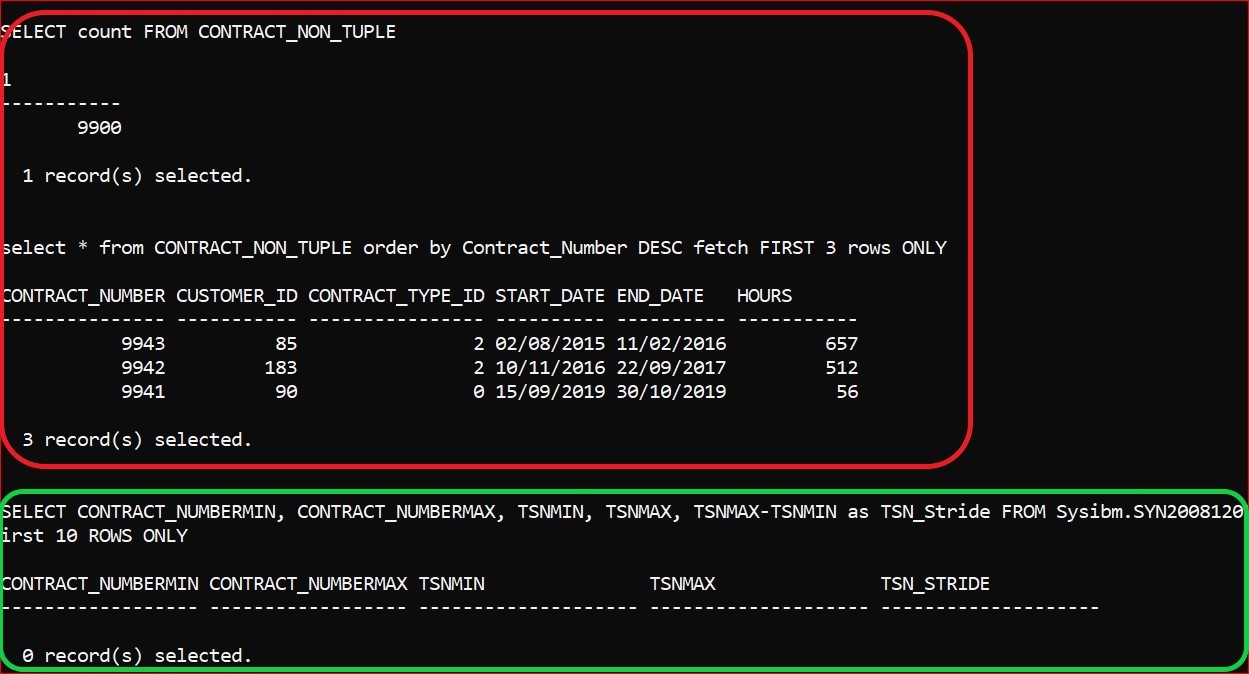
and restart the instance, you can repeat the experiment. Create a new table and then insert 9,900 rows and the synopsis table remains empty
The snippet below shows the count of rows (whatever) in the Base table (CONTRACT_NON_TUPLE) is 9,900 and the top 3 rows of data from that table, and then the empty Synopsis table
-
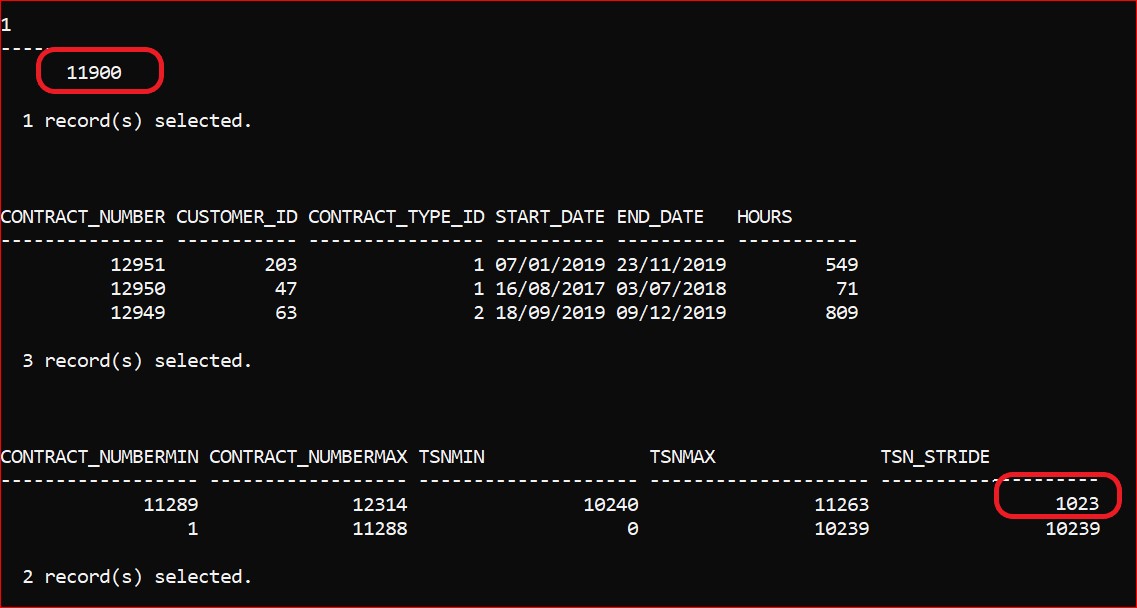
- I now INSERT a further 1,000 rows and here is the comparative picture:
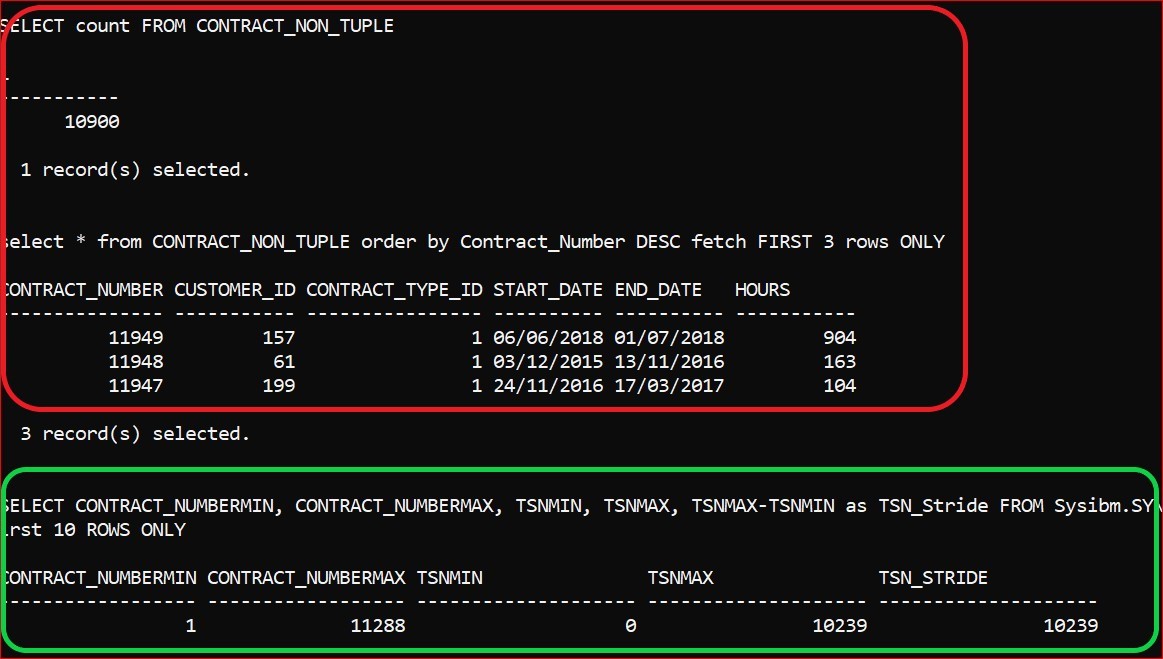
The increase to 10,900 rows of data has pushed past the threshold and provokes the insertion of a single row into the synopsis table.
Of course, that single row is of no use at all in data skipping: you can see that the ‘Stride’ encompasses pretty much the entire breadth of the data. Also, it will have reserved space and the size of the table will have jumped from 256 KB to 2,048 KB: larger, in this case, than the base table.
-
- If I insert another 1,000 rows, then we get an extra row in the synopsis table with a more ‘conventional’ stride:
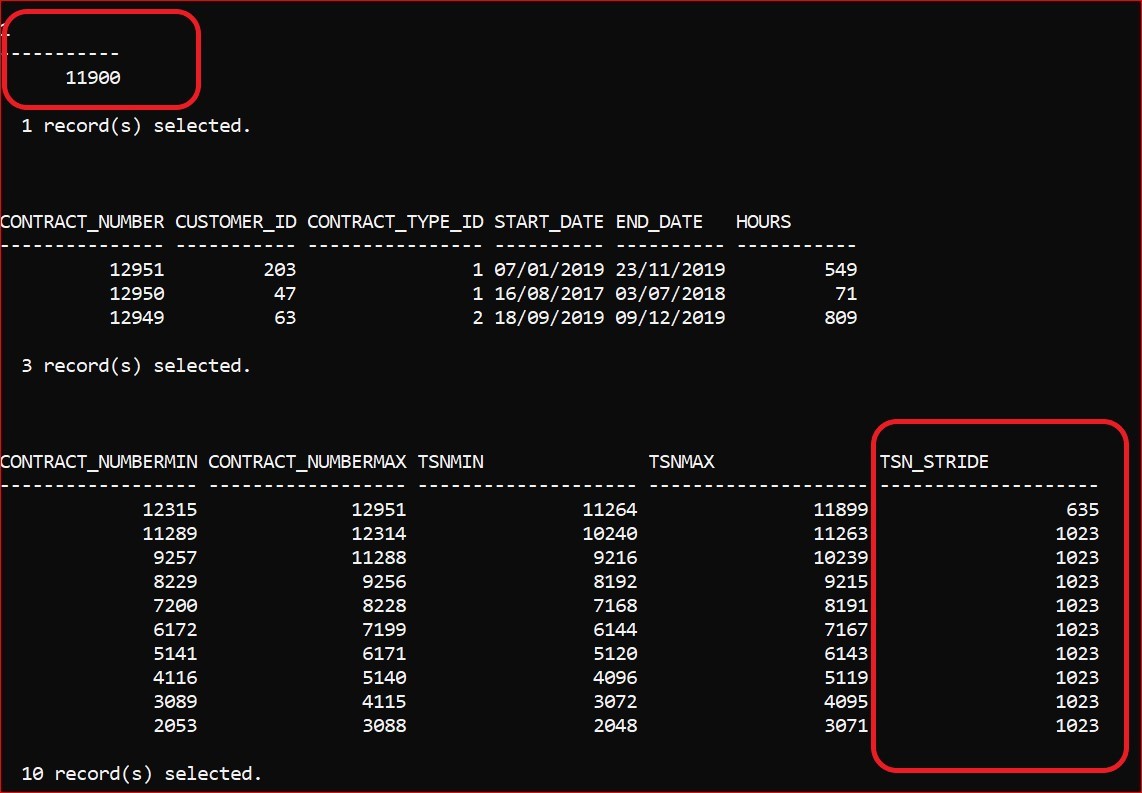
If, having deferred the population of the Synopsis table using this mechanism, you subsequently decide that the data has grown to the point where some data-skipping would be useful, you will have to EXPORT the data and LOAD it back in again. The data content will be the same, of course, but the synopsis table will have been rebuilt with conventional ‘strides’ to accommodate data-skipping:
This is also a useful performance feature when you have smaller column-organized tables, or where you’re loading the data in smaller chunks and using INSERT but needs careful management. Like DB2_COL_STRING_COMPRESSION=UNENCODED_STRING:YES it is not backward compatible.
Please have a browse around our Technical Blogs for more info on V11.5.4 Nebula or drop me an email at Mark.Gillis@Triton.co.uk