

It’s pretty straightforward surely? You take a backup and then restore it get back to some point of consistency. Not necessarily just in Production but maybe a test environment; set the data up as you want it, run a bunch of tests which trash the data, then put it back to that baseline position so you can do another set of tests. Or, more exactly, recover to a point part way through the tests, so that you don’t have to re-run all the initial bits that you already know work.
Or, in a Production environment, that dreaded 0:dark thirty call that says “someone has deleted x,000 rows or corrupted a table, or whatever. Can you put it back the way it was at whenever”?
But there are a bunch of options and a few gotchas. How do you get back to a Point-in-Time (PIT)? Do you need to? Why not just use RECOVER (it’s simpler)? Let’s have a look.
Backup
First off, let’s set up some test data and do some backups. I’ve got a very simple table set up in a database called FEDTEST.
I’m running v11.5.8 Community Edition on Windows 10 Pro on an AMD64 laptop with 12 cpus.
My test table is called USERS_TABLE and it looks like this.

The idea now is to INSERT some data and take ONLINE BACKUPs as I go along. The backups are run from another session so that they don’t disconnect the session doing the inserts, but I will do a COMMIT after each unit of work.
So, the sequence of events is
- Insert 2 rows and label as Unit of Work 1 (value of 1 in the UOW column)
- Take a Backup
- Insert a 3rd row as UOW 2
- Take a Backup
- Insert 3 more rows as UOW 3
- Take a Backup
- Insert 4 more rows but with a COMMIT after each one, so each is in a separate UOW
- Take a Backup
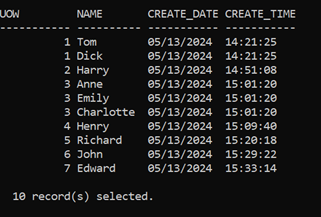
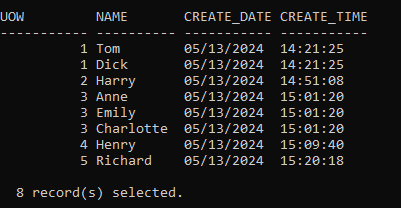
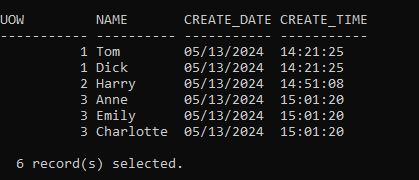
This will give us a set of test data like so
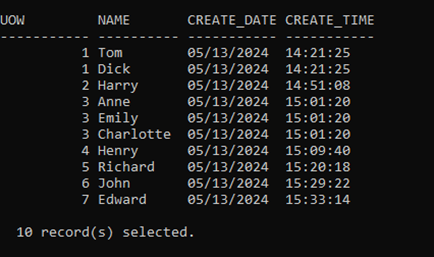
And a set of online backups like so

(offline backups associated with making the Log Archiving change active are not shown as they don’t form part of this test).
Test#1: End of Logs
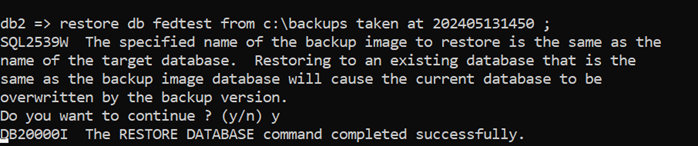
The first test is to RESTORE from the first ONLINE image (Backup Image 1) taken at 14:50. So, the command is as shown below. You will notice that
-
- The RESTORE is preceded by a CONNECT RESET. If you don’t do that, you’ll get the error SQL1035N The operation failed because the specified database cannot be connected to in the mode requested
- You are asked to confirm that you realise you’re over-writing an existing database. You can avoid these prompts by using the WITHOUT PROMPTING option
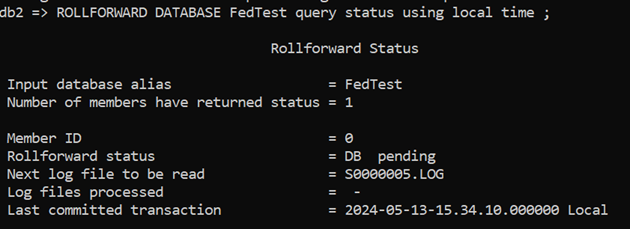
You can check what state the database is by using the ROLLFORWARD … QUERY STATUS command. I recommend using the USING LOCAL TIME option so that the timestamps associated with the Backups and the Timestamps you’re using for your ROLLFORWARD commands are in the same zone.
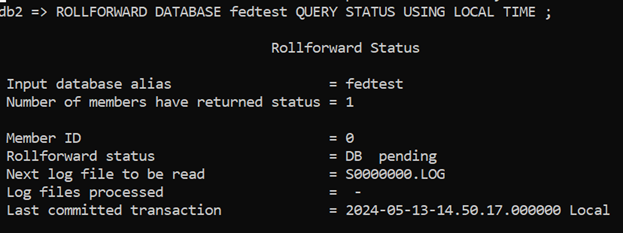
This gives us some useful information:
-
-
- ROLLFORWARD status is “DB Pending” status. In other words, the database is not accessible and it is waiting for you to decide which ROLLFORWARD options to exercise: which transaction logs you are going to apply
- Next Log File to be read. This might not be the final log file, but it is where the ROLLFORWARD operation will start.
- Last committed transaction: the timestamp on this is 14:50 on the 13th May so, if you look at the contents of the table from before the restore, you can see which transactions you could expect to find in the table as things stand (assuming the database was accessible) i.e. everything before 14:51:
-
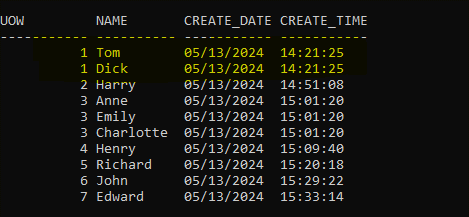
However, I am going to issue the ROLLFORWARD command with the option TO END OF LOGS AND COMPLETE. This will execute and give us the status below.
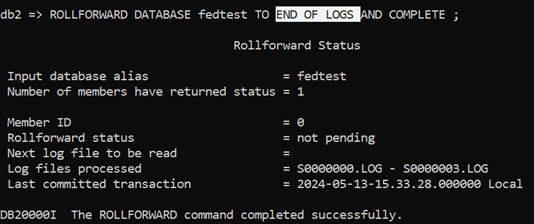
-
-
- ROLLFORWARD status is accessible (it’s ‘not pending’)
- Next Log File to be read value is blank i.e. there is nothing more to be done and
- Log files processed now shows a range of log files from S0000000 to S0000003. In other words, if you look at the display of information about Backup Images; all the log files for all of the available images:
-

And, sure enough, all the data; 10 rows, 7 Units of Work, are available in the table.
Gotcha#1
Something to bear in mind, particularly if you attempt multiple RESTORE or ROLLFORWARD operations is that
“ A new log chain is created when either a database roll forward to point in time is performed or when a restore without rolling forward is performed”
So, there is now a new sub-folder:
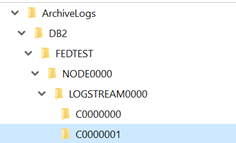
Effectively what has happened is that Db2 has reflected the RESTORE action as a new database. You may think you have restored an old one, and over-written what was there, but Db2 has kept a record of what went on before and where we are now.
What I am going to do now is to copy all of the logs from the original Chain ID (C0000000) to another folder. More on that later.
Test#2: End of Backup
Next test is very similar, but we’ll use the END OF BACKUP option to not ROLLFORWARD through any transaction logs.
I’m going to use the Backup Image 2 taken at 14:55. Here’s the status once that and the ROLLFORWARD have been done.
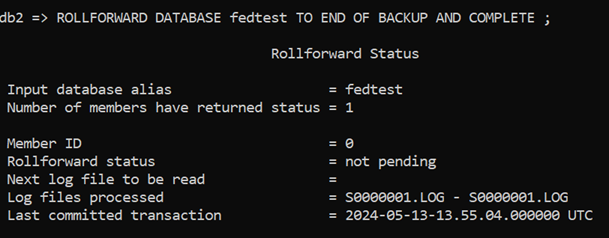
-
-
- It has only processed Log File S0000001.LOG
- Last committed transaction is now timestamped 13:55, so we should only see the first 3 rows
-
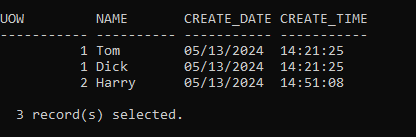
The operation has successfully restored Backup Image 2, which only contained the 3 rows of data that were committed and stored within that backup.
Test#3: ROLLFORWARD to Point in Time (PIT)
But what you would probably want to do, in a Production scenario at least, is to RESTORE to a specific time; the point just before things began to go wrong.
So, we’ll restore Backup Image 1 again (which only contains the first 2 rows; the ones in UOW 1) but then we’ll ROLLFORWARD to a Point In Time that is later than the end of that backup. I’ll aim to get data up to and including the row for ‘Richard’, which was committed at 15:20, and which is, therefore, contained in Backup Image 3.
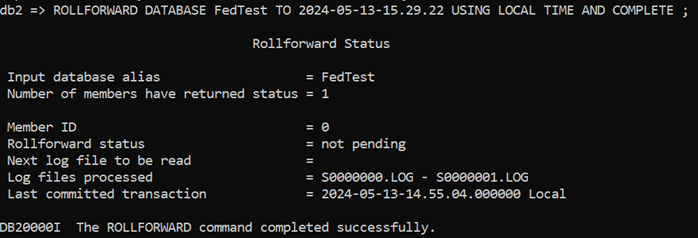
But look at what the ROLLFORWARD Status is telling us:
-
-
- It’s not pending, so it’s accessible but
- It’s only processed the first 2 log files
- The last committed transaction is from 14:55
-
It only has the first 3 rows of data:
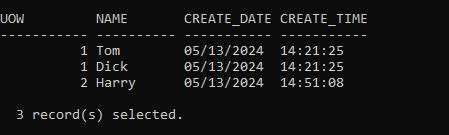
That isn’t what I wanted at all. Why has this happened?
Well, you remember that Gotcha discussed above; about the new sub-folders created for new Chain IDs? What has happened here is that the RESTORE has found a more recent Chain ID than our original one and has processed the logs from that. They do not contain the row I want to see: ‘Richard’, which has a transaction time of 15:20.
To get to that specific transaction and PIT, I need to use the OVERFLOW LOG PATH option and to point at the location where I stored the Archived Log Files (also described in Gotcha).
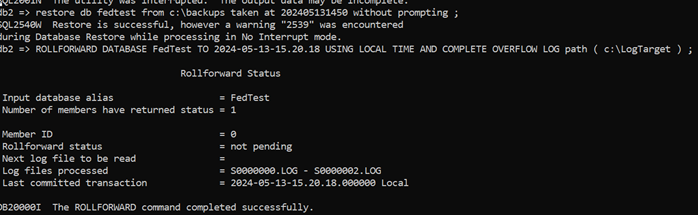
What we can see there is
-
-
- Log files processed now also includes S0000002.log
- Last Committed transactions is now from 15:20
- This means we now have all rows up to and including ‘Richard’
-
Test#4: RESTORE and Complete
This should be a little simpler. This is just a RESTORE from a specific backup image but with no requirement to apply any archived transaction logs. I’m going to use Backup Image 3

Which, because it started at 15:03 and only contains the transactions committed in S0000002 will just have the first 6 rows of the table included:
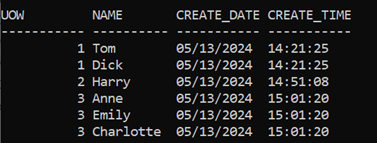
That’s all I need; just the first 3 Units of Work (UOW 1,2 and 3), so I will run the ROLLFORWARD with a simple COMPLETE option to call it a day with whatever is in the Backup Image.
But I get this

That’s confusing on a number of levels; it’s talking about a timestamp from before the test started. That’s because it’s using UTC not Local Time. So, I run a Query Status and specify Local Time:
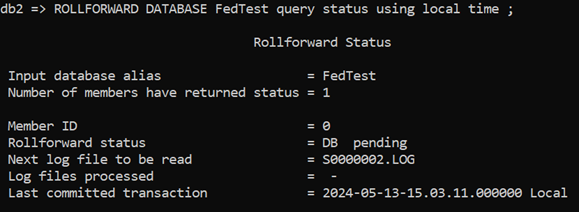
Well, that looks OK. It’s looking for the S0000002 log and it has already committed up to 15:03 so it should be processing the remaining 3 rows for UOW 3 that I want. I suspect it’s that Chain ID issue again, so I’ll direct it to the location where I have stored the original logs:

That still fails (although it has now worked out to use Local Time). The only way out of this is to use the PIT options from the previous test to take the RESTORE up to the transaction time for the last of the UOW 3 rows.
You can see the Query Status command quoted a Last Committed Transaction timestamp of 15:03:11, so let’s use that:
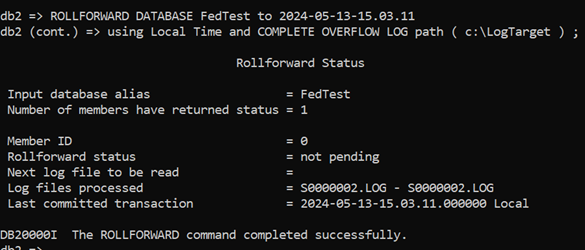
And we now have just the rows we want
Test#5: RECOVER
Another option is to use RECOVER. It is simpler than RESTORE in many respects; not least as you don’t have to use ROLLFORWARD or specify the backup image location. It will interrogate History File to find the information it needs. So, a basic version of the command might be
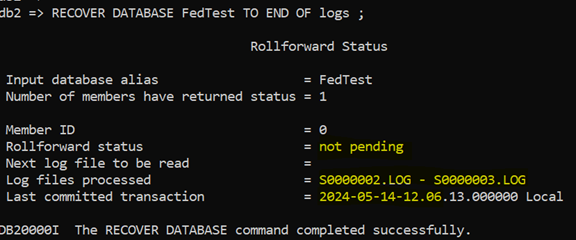
No ROLLFORWARD was run; the database has been processed as far as it can:
-
-
- ROLLFORWARD status is “not Pending”
- Log files processed shows S0000002 and S0000003
- Last committed transaction is 12:06 on the 14th. Which is later than all our test data.
- But it only has the 6 rows from UOW 1,2 and 3
-
This is because it has picked up the History File and Chain ID information for today’s activity and the last thing we did was Test#4: RESTORE and Complete
Test#6: RECOVER to PIT
So, what I need to do is to specify an actual PIT. I’m choosing one that is beyond the end of the last one to demonstrate that it can find the requisite images and logs
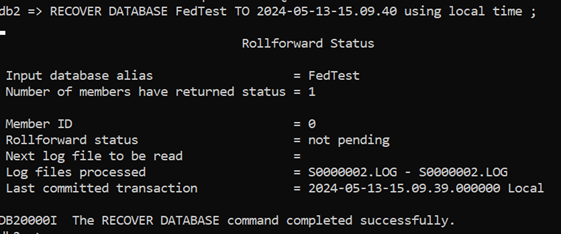
Which it has
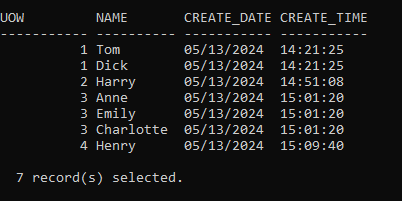
Test#7: RESTORE from a FULL OFFLINE BACKUP
And a RESTORE from an OFFLINE BACKUP. Arguably the simplest option and one that I could have started with but that doesn’t address the issues of recovering to a point that either allows you to restart testing (if it’s a DEV or Test environment) or to a pre-corrupted point (if it’s Production). It relies on the existence of a backup that was taken when no-one was connected and no application activity was occurring.
Luckily I took one after setting up my test data:

So, I can just specify that timestamp although NB you will still need to execute a ROLLFORWARD:
Bear in mind that, because this is an OFFLINE Backup it does not include logs. I had to go and retrieve the S0000005.LOG file from the active transaction log directory and copy it to my Overflow log path. Then the ROLLFORWARD completed successfully:
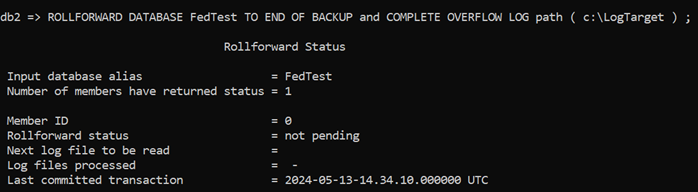
And all my test data was back:
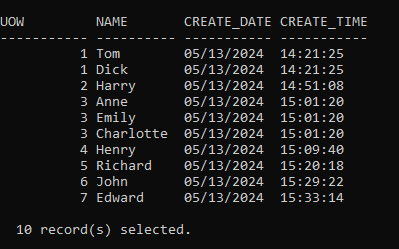
Test#8: Invalid PIT
Gotcha#2
This is something that happened in Test#4: RESTORE and Complete really.
Restore from Backup Image 3

RollForward to a Point in Time that cannot be reached (I didn’t specify Local Time so it’s using UTC)

Re-issue the RollForward for a valid Point in Time (Local Time now used)
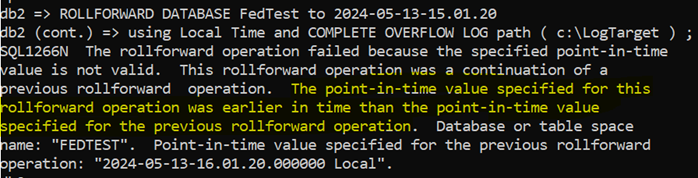
All you can do is CANCEL the ROLLFORWARD and start again with the RESTORE and get the PIT options right.
Conclusion
I guess the salient points of this test are
-
-
- BACKUP, RESTORE and RECOVER are all quite complex, or at least, offer a great deal of complexity and need to be processed with care and the right options.
- Keep a copy, or the original set of archived logs from the original Chain ID. You might need them if your first RESTORE doesn’t achieve the right result.
- When you design your BACKUP strategy, give some serious thought to how your RECOVERY strategy needs to operate. We haven’t even touched on INCREMENTAL and DELTA backups yet….
-
I’ve worked on sites where Db2 Backup was dismissed as not up to the job. I don’t believe this is true. The Backup, Restore and Recover options can give you everything you want to operate a database in a 100% reliable and recoverable way, but you need the right tool for the right job. You can’t complain that hammering a nail in with a screwdriver doesn’t work…
However, these are only my opinions and observations. If anyone wants to make suggestions or offer better ways of doing this, please email me at mark.gillis@triton.co.uk