

Introduction
In my previous blog articles on Db2 Pacemaker HA clusters (which you can find here and here), I demonstrated how these clusters can be put together, configured and used in the most resilient way.
Or at least I thought so at the time – the testing of the transactional workload’s behaviour during a failover showed that the first transaction to happen at the time or after the failover would invariably fail with the error:
SQL30108N A connection failed in an automatic client reroute environment. The transaction was rolled back.
This meant that, even if the remote client connections could survive the failover (via ACR) and continue their processing without any external assistance, some data would still have been lost and required either extra application logic or a manual intervention to deal with the problem.
However, very recently I stumbled upon a new feature, (new to me), called the “Seamless Failover”, which promised even better resiliency for the remote clients during a failover.
From the Db2 KC:
“If the SQL statement that fails [in a failover] is the first SQL statement in the transaction, automatic client reroute with seamless failover is enabled, and the client is CLI or .NET, the driver replays the failed SQL operation as part of automatic client reroute processing. If the connection is successful, no error is reported to the application, and the transaction is not rolled back. The connectivity failure and subsequent recovery are hidden from the application.”
So, let’s see how this “Seamless Failover” can be configured and what benefits it brings to our remote clients.
Seamless Failover Configuration
The Db2 documentation is very clear on what must be done on the client to configure the Seamless Failover (link) in ACR environments:
- You must enable both the enableAcr and enableSeamlessAcr keywords.
And that’s all, very simple indeed!
(there are other conditions required to establish a seamless failover connection, but they dictate runtime requirements and are not a part of the client configuration, we’ll check these a bit later)
For the purposes of this testing, I used a standard Db2 client running on Linux, so to update the client configuration, I needed to edit the following file:
sqllib/cfg/db2dsdriver.cfg
If the file isn’t already there, it can be created with the following command:

In my case, the file hadn’t been already present, so I created it and then added the extra options required for the seamless failover (shown below in red colour).
The whole db2dsdriver.cfg file looked like this:

Those few extra parameters (maxAcrRetries, acrRetryInterval and affinityFailbackInterval) I have picked up somewhere along the way and they are not strictly required to enable the seamless failover. But I did all the testing with those parameters present, so I kept them here for completeness.
Having updated the configuration accordingly, the next step is to run some tests and confirm the seamless failover is functional.
Testing
All following tests were done from the Linux command line on a standalone Linux server, acting as a remote Db2 client, with the TCP/IP connectivity to the remote Db2 HADR nodes (also Linux).
Since only CLI and .NET remote clients are supported for the Seamless Failover, I used the db2cli tool to make sure my workload was compliant 😊 (executing the commands via CLP, i.e. using the “db2 <command>” syntax, won’t work because CLP does not use the CLI protocol).
Test 01: Simple Transactions in a NON-Seamless ACR environment
The purpose of this test is to establish a “baseline”, that is – to see what exactly happens with the transaction workload when there is no Seamless Failover configuration in place.
The workload consists of 4000 INSERT statements into a TEST table (which should provide enough time for a failover to intercept the execution of the workload) and is stored in a file named DW_TEST_CLI_script_05.sql:

A few notes on the workload:
- All the rows from the TEST table are deleted at the start of the workload, to ensure a clean start.
- The only reason I am using a SELECT-from-INSERT here, and not a simple INSERT, is to have the actual values inserted into the table also displayed in the output.
- Each INSERT is immediately followed by a COMMIT, to split the workload into 4000 short transactions.
Before running the test, the Seamless Failover is disabled for the client by updating its configuration in the Db2DSDRIVER.CFG file:

Having done that, the workload execution can be started:
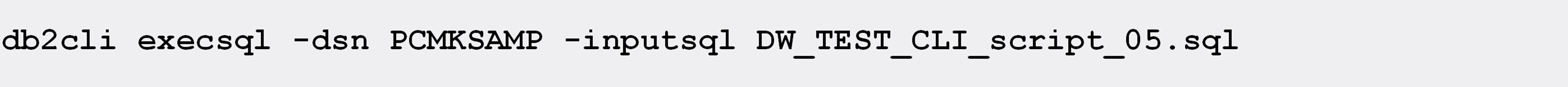
A few moments after the workload has started, the failover on the HADR Standby is initiated (and completed after a short while):

Finally, when the workload has completed as well, we can examine the results to find what happened during the non-seamless failover:
[showing just the relevant bit of the (very long) output here]

As expected, the first transaction to be executed at the time of the failover, or just after it, has failed.
This is highlighted above in the red colour.
All other transactions, up to the last one before the failover (ID=589) and the remaining transactions after the one that failed, have been successfully completed.
This can be further verified by inspecting the TEST table:

According to this, only one row is missing in the TEST table, as it contains 3999 rows and we executed 4000 inserts.
In conclusion, this test demonstrated what happens in a non-seamless ACR environment during a failover: even though the client is automatically rerouted and can proceed with the workload processing, still the first transaction to be executed at the time of the failover or after it will be rolled back and must be somehow recovered later on.
TEST 02: Simple Transactions in a Seamless ACR environment
This test will show us what happens to the same workload (4000x INSERT+COMMITs) in a Seamless Failover Environment.
To enable the seamless failover, once again we must do a (very simple) update in the client’s configuration, in the Db2DSDRIVER.CFG file:

Note: no client restart is required after the config update!
With the Seamless Failover enabled, we can start the workload execution once again:

Again, a short while after the workload has started, the failover on the HADR Standby is initiated and completed a few moments later:

The workload output now looks like this:

We can clearly see that in this case, when the Seamless Failover is enabled, the first transaction to hit the failover (ID=681) completes successfully, and the workload continues uninterrupted and with no transactions missing!
This is further confirmed by checking the contents of the TEST table:

All four thousand rows are now in place, no data has been lost!
TEST 03: Large Batch Job in a Seamless ACR Environment
This is the last test in this series, and it will try to demonstrate what happens to a large(r) batch job executing in a Seamless Failover ACR environment.
By a “larger batch job” I mean running a larger number of statements in one (larger) transaction, before issuing a COMMIT statement. In this case we will once again execute the same 4000 SELECT-FROM-INSERT statements as before, but only COMMIT once at the end of the processing.
Now, if you remember what was written at the beginning of this article, one of the requirements to achieve a seamless failover was:
“If the SQL statement that fails [in the case of a failover] is the first SQL statement in the transaction”
This test will aim to do just the opposite – execute an (arbitrary) number of statements before having a statement fail during a failover. And then have some more statements to execute to get to the end of the workload processing.
So, let’s see what happens in this case!
Just to make sure, the Seamless Failover is still enabled in the client configuration file:

Our test workload file (DW_TEST_CLI_script_06.sql) now looks like this:
Running the workload, same as before:

…and initiating the failover right after the workload started running:

When everything is done, the workload output shows the following:

So, what exactly happened there?
- The first 596 insert statements were executed before the failover (time=07:30:31), and they completed successfully, but without a COMMIT.
- The 597th INSERT statement failed with SQL30108N and was rolled back.
- Since no COMMITs were done by this point, this means all previous INSERTs were rolled back as well (we will confirm this later on)!
- Worryingly, the client workload was then automatically rerouted and continued processing as if nothing had happened.
- The IDs being inserted just after the failure once again started with ID=1, this is because the rollback removed all inserted rows, and the table was once again empty.
Weird stuff!
To further confirm the above, we inspect the data present in the TEST table:

Simple math (4000 total INSERTs minus (596+1) failed == 3403 rows in the table) suggests that only the rows before the FAILOVER have been lost.
The timestamps (TS) in the TEST table prove that it contains only the rows inserted after the failover:
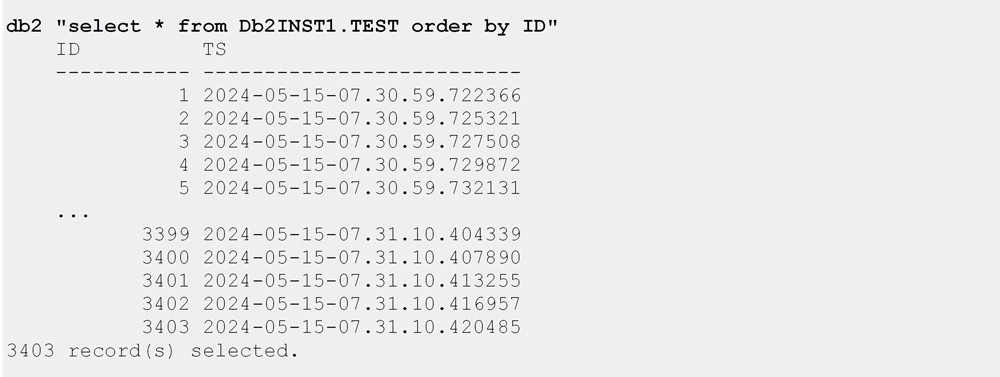
Obviously, the rest of the workload has made it into the TEST table, so the final result is that our (larger batch) workload has only partially completed.
This is indeed a very weird and very messy situation, which I wouldn’t want to ever have in any production environment that I am responsible for. Mostly because the ensuing cleanups might prove to be even messier…
What I am (most likely) missing in this test, which is (probably) responsible for such an erratic result, is some form of an error handler in my client “application”, running the workload, which would have caught the SQL error code returned (SQL30108N) and terminated the whole batch process. This would have resulted in a cleaner situation – nothing at all would have been written into the TEST table (especially not a partial result) and the batch job would have been easier to resubmit, with no extra cleanups required.
Sadly, the db2cli utility that I used here doesn’t seem to have such an option to trap SQL errors (or at least I haven’t found one), and therefore I wasn’t able to test this scenario.
Conclusion
In this article we have seen how a very simple update to the client configuration can have a very positive effect on the transaction processing, allowing (simple) in-flight transactions to complete even when they are executed right at the time of the failover, resulting in a zero data loss.
But there is that hiccup with more complex transactions, consisting of more than one SQL statement, where only partial processing might happen, which should (probably?) be taken care of by special error handlers. This is certainly something that I’d be very eager to test at some point (and when that happens, time and resources allowing, I promise to write an update to this article).
NOTE: The seamless failover environment can be set up for JAVA clients as well as the CLI (or .NET) clients, which I exclusively wrote about in this article. The reason for this omission (of any setup/testing with the JAVA clients) is fairly simple – I don’t have a suitable JAVA client that I can use to carry out the testing. Even if there are readily available Db2 JAVA clients out there, that can be downloaded, installed and used for free, I apologise for being a lazy DBA and not doing any of it, but will instead point you to a few pages in the Db2 KC where you can get all the details: here, here, here and here. All this should be very similar to the CLI concepts explained in this article.
"APIS IT have been working to deliver a programme that moves a set of extremely important applications onto new Linux Db2 based systems. Over the past 2 years, Triton Consulting has been a trusted supplier to us as they have provided us with technology expertise in Db2 to help us when we haven’t got the expertise internally. Damir’s expertise in Pacemaker in particular has proved essential to us. "
Robert Stanko - Director, IT Support at APIS IT d.o.o.
Configuring Db2 Pacemaker HADR cluster with QDevice in AWS
Damir Wilder demonstrates how a Db2 Pacemaker/HADR cluster with a QDevice can be deployed on RHEL9 virtual servers in the AWS VPC environment.