

In Part 1 I showed how to setup a simple TSA/HADR cluster consisting of two servers, and what happens to an active client connection in case of a failover.
In Part 2 we saw how a client with configured ACR automatically recovers its connection to the database in case of a failover in the cluster.
In this Part, we will reconfigure the TSA/HADR cluster to use the VIP (“Virtual IP address”) and also remove the ACR configuration, in order to see how the VIP on its own affects the client processing during and after a failover.
TSA/HADR failover with VIP
For those who don’t know what VIP is and missed the above hyperlink, VIP is nothing more than a simple TCP/IP alias that TSA dynamically assigns to an active NIC (eth0 or em0 for example) on the HADR primary server.
First, let’s remove the ACR configuration from both servers:
Primary (ITCHY, 192.168.20.64):

Standby (SCRATCHY, 192.168.20.65):
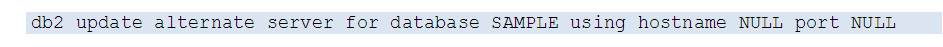
The change is visible on the client as soon as a connection to the database is established:
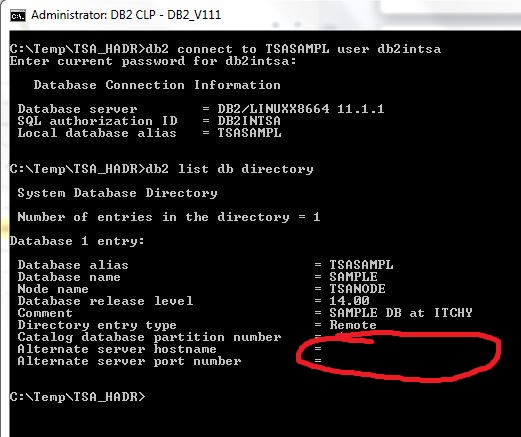
In order to configure VIP, we must first completely delete the existing TSA domain and then recreate it with the appropriate configuration.
Let’s do this step by step:
TSA domain is deleted by issuing the “db2haicu –delete” command on both servers (or cluster nodes). The effect is immediate and is checked with “lssam” command (shown here only on ITCHY):
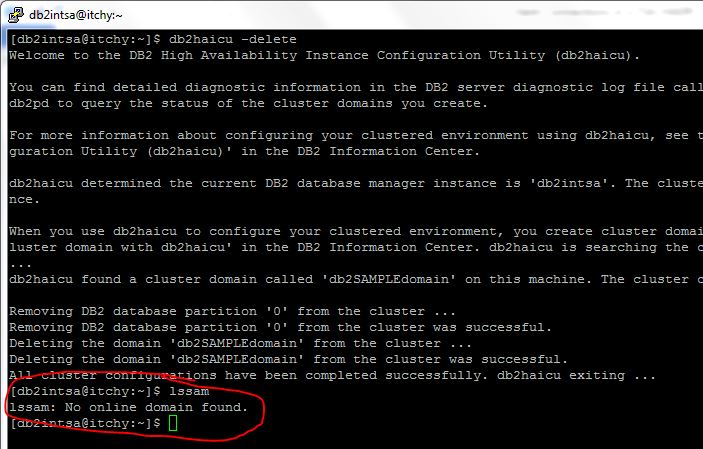
(should the command fail for whatever reason, this link provides instructions how to delete the TSA domain by hand)
Next, TSA XML configuration files on both servers are edited to include the VIP configuration:
TSA_SAMPLE_primary.xml (on Itchy):

TSA_SAMPLE_standby.xml (on Scratchy):

Finally, the TSA cluster is configured and started with updated configuration files:
First on the Standby server (SCRATCHY):
Then on the Primary server (ITCHY):

VIP configuration and current status (Online) is again checked with “lssam” command, together with the rest of the TSA/HADR cluster resources:
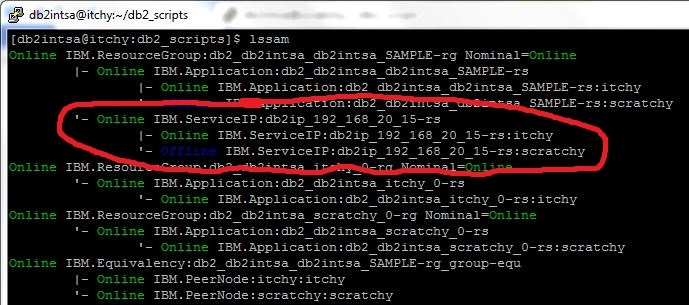
With all that done, the reconfiguration of server side is complete.
Let’s now reconfigure the client to use the new VIP address:
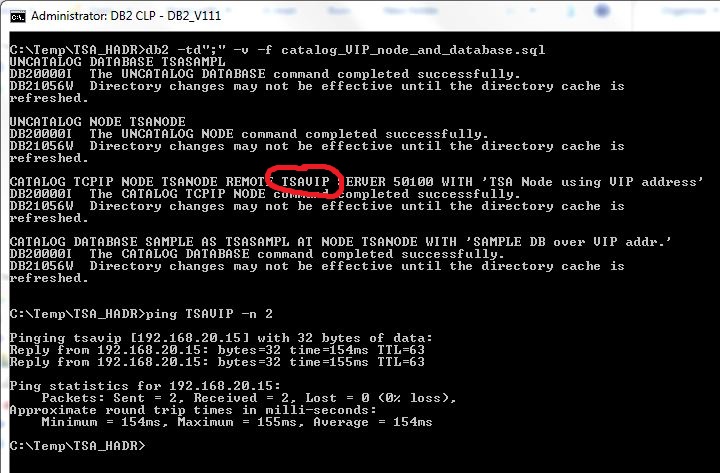
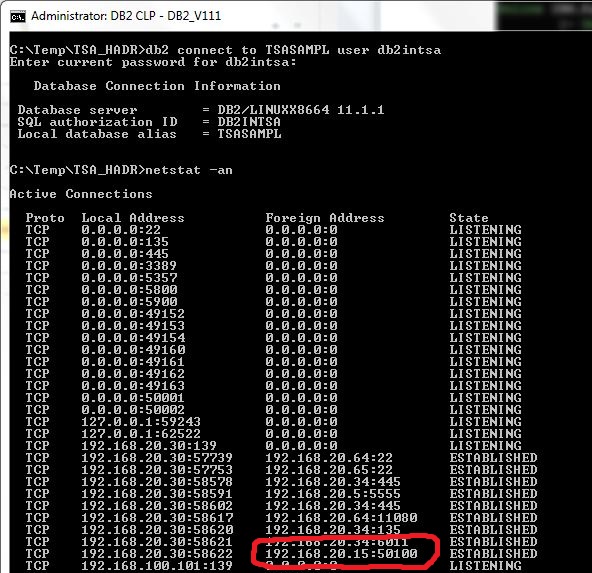
Test the client connection and prove that it now connects to the VIP address:
Execute the failover with both servers and client setup for VIP:
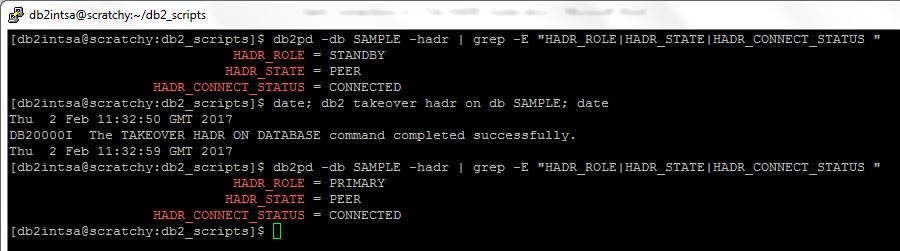
This is what happens to the client’s batch job during a server failover with VIP only (no ACR):
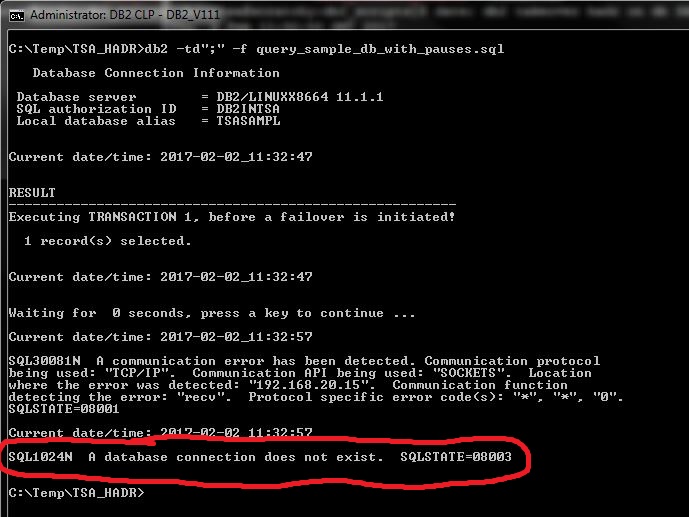
Transaction that was in-flight at the time of the failover is expectedly rolled back.
What is new here is that the client loses the connection to the database and does not reconnect automatically (even though the database’s TCP/IP address remained unchanged after the failover), and is therefore unable to continue its batch job processing. This is similar to the “plain” TSA/HADR setting (no ACR, no VIP), except for the following:
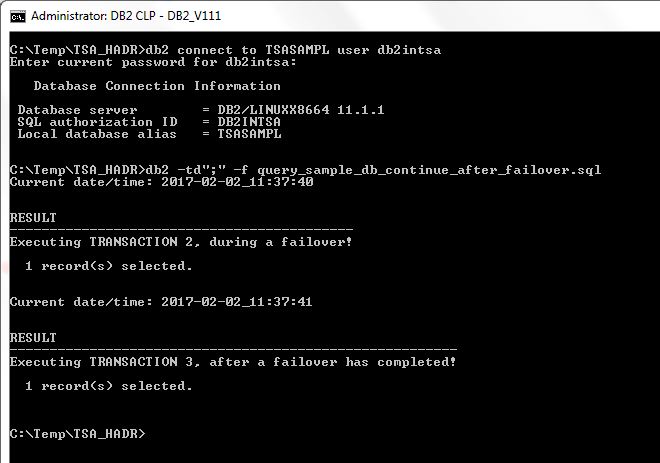
After the explicit reconnect to the database, the batch job can be restarted:
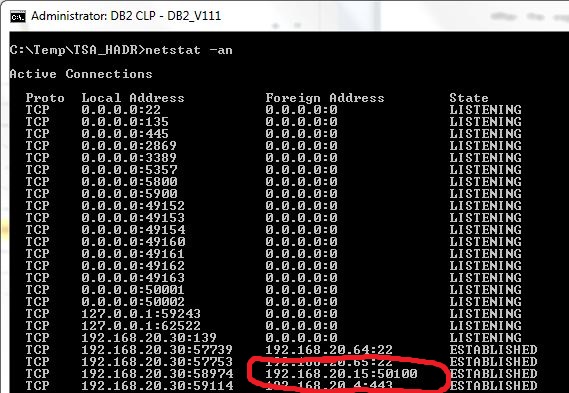
The following screenshot shows that the client is still connected to the same TCP/IP address – the VIP address:
Conclusion
Using the VIP address enables the client to always connect to one and same TCP/IP address, regardless of which server is currently active in the TSA/HADR cluster.
However, without ACR in place, the client loses the connection to the database and does not reconnect automatically, so it cannot continue its batch job processing before explicitly reconnecting to the database.
It is debatable whether a user intervention is required or not to reconnect to the database – there certainly are applications and technologies out there that are smart enough to detect the loss of database connection and reconnect automatically (and continue their processing). But, for a simple script job such as the one used in this exercise, a user intervention is still required.
In Part 4 we will put ACR and VIP to work together and see what happens to the client’s batch job in that case.