
I’ve been doing some migration work; porting a Db2 database to a PostgreSQL one. You could say that is going from an Enterprise strength solution to a simpler, but less expensive option, but it’s not a choice I’m in a position to ignore.
Customers are being presented with a wealth of database options as they migrate to the Cloud, and many of them are embracing the options of simpler and less licence hungry products.
There are many positives to PostgreSQL but there are some pitfalls in attempting such a migration.
Here are a few notes.
Syntax
There are a few syntactical differences that I’ve stumbled over, but I suspect there are a lot more. Some examples are
- Date functions e.g. YEAR aren’t available. To extract the Year from a Date or Timestamp you’d use
EXTRACT( YEAR from CURRENT_DATE ) orDATE_PART('year', CURRENT_DATE ) – 1
- Date differences: in Db2 you might use
TIMEDIFF(TIME(brakes_off) , TIME(brakes_on)) or((MIDNIGHT_SECONDS(brakes_on) - MIDNIGHT_SECONDS(brakes_off)) / 60)
to find the number of minutes (or days, or months, or whatever) between two timestamps.
In PostGreSQL you would simply use
-
-
Brakes_On - Brakes_Off
-
(Both columns are defined as a TIMESTAMP, but this works with TIME or DATE too). The main difference is that PostGreSQL will return a result of type INTERVAL as opposed to the INTEGER that Db2 returns. This type takes a bit of extra handling (it can’t be cast to a numeric data type, for instance) but is actually more representative of a difference between 2 dates or times.
Partitioned Tables
Db2 allows you to create the partitioned table with a single statement:
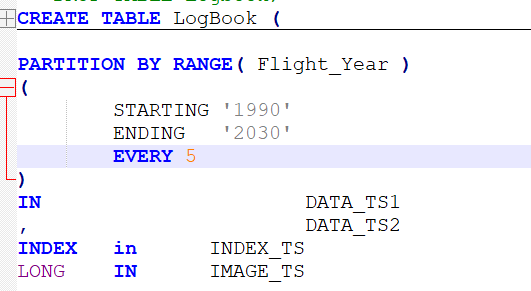
(Column details, constraints, etc. are omitted for conciseness’ sake). This will create a table, with 11 partitions, distributed across alternating data tablespaces and with Index and LOB tablespaces specified too.
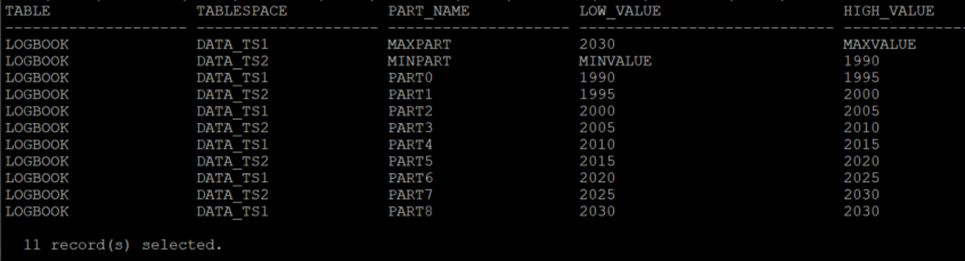
- To accomplish the same thing in PostgreSQL, you need to define the table, and then each partition as a separate table.
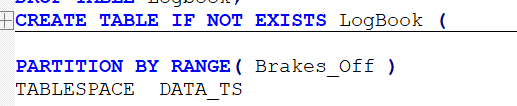

- Another difference is that the Db2 version can take advantage of a generated key. There is a timestamp called BRAKES_OFF so a column called FLIGHT_YEAR can be defined as
NOT NULL generated always AS ( YEAR(BRAKES_OFF) )and that is used as the Partitioning Key.
PostgreSQL cannot use a generated column in the partition key.
- A further difference is in defining whether the specified value for the Partition is Inclusive or Exclusive. Db2 gives you the option to define this; PostgreSQL specifies that “When creating a range partition, the lower bound specified with FROM is an inclusive bound, whereas the upper bound specified with TO is an exclusive bound”
Triggers
Somewhat similar; in Db2 you can define a trigger and it’s embedded SQL in a single statement. One that I use sometimes is an “Instead Of” trigger which allows an INSERT to be done on a VIEW, by decomposing the statements under the covers into separate INSERTS to the underlying physical tables. So, the statements look like this
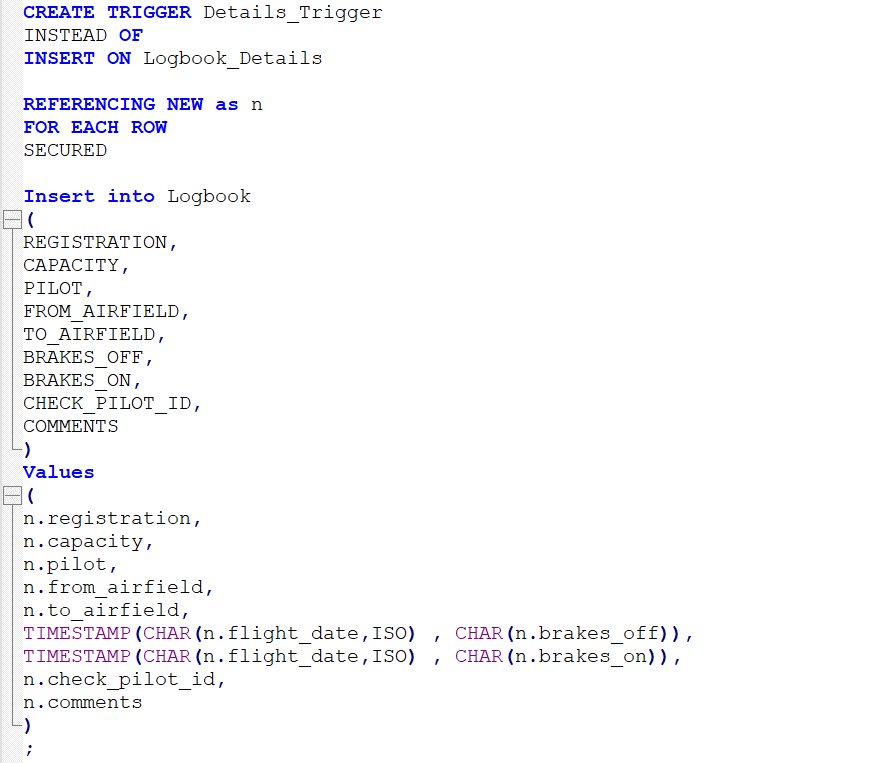
To accomplish the same thing in PostGreSQL, you have to create a function with the SQL in it, and then reference that from a trigger. So, part 1 is Create the Function with the required SQL statement(s) embedded in it:
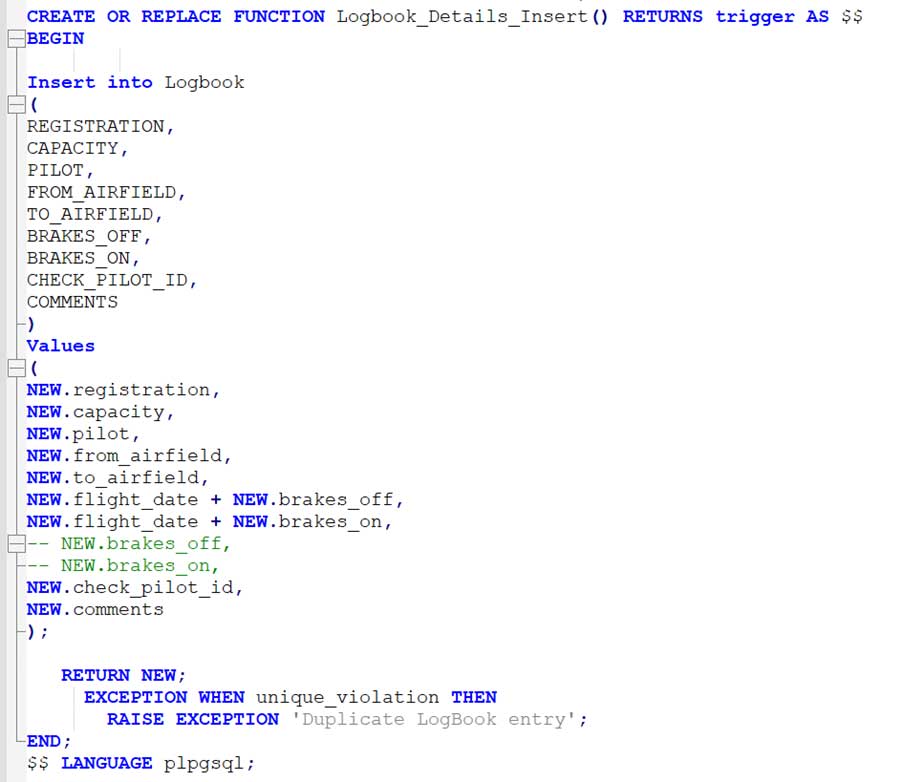
And Part 2 is to create a Trigger that references that Function:
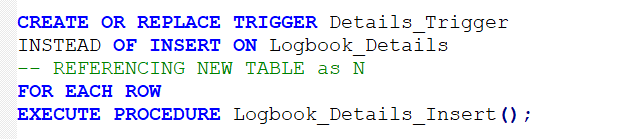
Stored Procedures and Functions.
Then there are Stored Procs. You’ll have noticed some differences in the way the Function in the previous section was coded; it looks a bit different to Db2 and some of those differences are apparent in Stored Procs too.
Fundamentally, it looks like some of the things you’d define using a Stored Proc in Db2 is going to be done as a Function in PostGreSQL. Stored Procs only appeared in PostGreSQL at v11 so it might be that the technology hasn’t caught up yet, or it might be that a PostGreSQL Function is a more robust solution anyway. Documentation states “PostgreSQL does not support true stored procedures (multiple result sets, autonomous transactions, and all that) though, only sql-callable user-defined functions.”
But this might actually be a better option. In my Db2 database I have a Procedure called Days_Since_Last_Flight. It does what it says on the tin; works out when the last recorded flight was in the LOGBOOK table and subtracts that from the current date to give a figure, in days.

But if I want to embed that code into a SELECT statement, I’ll need to define a Function to call the Procedure. Otherwise

But PostGreSQL struggles with embedding this SQL into a Procedure, so you end up with just a function anyway:
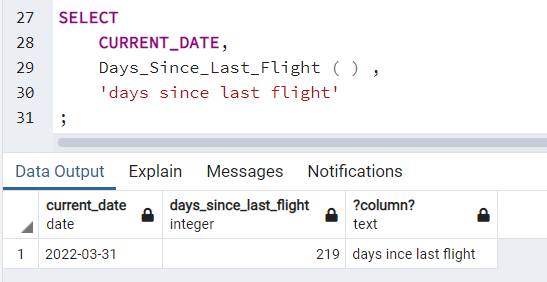
The problem would be the performance consideration; a Procedure will be executed within the database, whilst the function will need to externalise the result set to pass it back.
Backup and Restore
Like some other ‘simple’ relational database products (e.g. MySQL) the backup routines are not especially complex and really just dump out SQL, rather than produce a binary image as Db2 does. The PostGreSQL commands to take a dump of a database would be
pg_dump -d database_name -U userID > target_file org_dump -d database_name -U userID --data-only --column-inserts > target_file
The first one will reverse-engineer out all the DDL to create all the objects from the database and then append a COPY statement to put data into the tables.
The second will just do the data, as a series of INSERT statements.
The story so far
I’m deliberately avoiding the term ‘conclusion’ here as this an on-going investigation and these are just some of the items I’ve stumbled over so far. Rather than presenting this as a technical blog, I’m hoping to excite a bit of debate or at least open out the topic for wider discussion. Anyone have any experiences that they would like to share or pitfalls (or bonuses) they have found in similar migrations? I’m a Db2 guy at heart but finding more and more that I need to embrace the other available RDBMS options as we explore options to migrate to the Cloud and elsewhere. Comments welcomed.