

JavaScript Object Notation (JSON) is an open standard data interchange format that has been around since the early 2000s but is gaining more and more traction these days. As such, it behoves us in the database community to ensure that we can store it and process the data.
It’s arguably more flexible than XML and it seems to be moving into a space that XML occupied. Back in the day, I spent a lot of time getting to know the pureXML features and functions introduced with, I think, Db2 v9 (codenamed ‘Viper’) back in 2006 but I don’t think I ever got a really worthwhile return on the time that I invested.
Perhaps IBM feel the same and are reluctant to pour a lot of time and effort into providing dedicated functionality for JSON, or perhaps this format’s sheer flexibility means you don’t need this.
With the XML data type, you can store well-formed XML documents in their native hierarchical format. JSON data has to be formatted into a string and loaded into a CLOB or BLOB data type, thereby losing the straightforward human-readable format of the JSON document.
There are, however, several JSON functions in Db2 that allow data to be transferred to, consumed by and analysed within (and without) Db2. I’m going to explore these in the next blog but here with some ‘real-life’ examples of how to get your JSON data into Db2.
Getting the data in
I’m going to use two different data sources in this blog; the first is my ‘all-purpose’ R&D database: LogBook. It’s a very simple database with a very small footprint but, because I use it as the starting point for most of my Db2 testing and experimentation, it’s probably the most over-engineered database in the world.
At its heart is a simple table called LOGBOOK that stores details about flights I’ve made; when, where and any other relevant details.
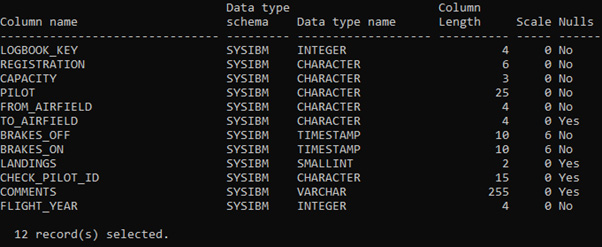
The last 10 entries are fairly representative (I’m not showing the full result set, for brevities sake)
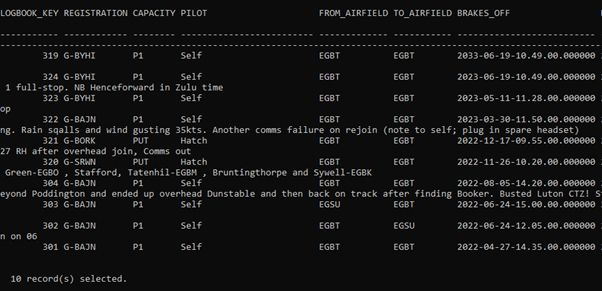
I want to extract a sub-set of this relational data in JSON format and use that to transmit the data to another database (Db2 in this case, but one of the values of this is that it could be almost any software. More on that later).
To do this, I’ve used JSON_OBJECT scalar function in a very simple form:
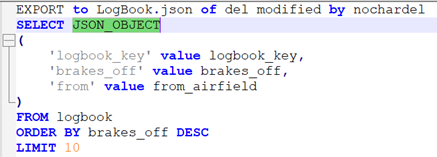
And that gives me a nice concise set of data to transport:
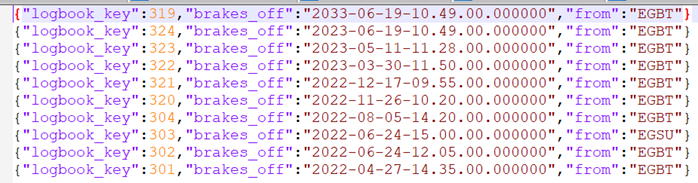
Note the curly bracket at the start and end of each line; that means that each row is a single JSON object, whilst the key/value pairs are separated with a colon.
I can then connect to my target database and IMPORT this data into a table with a CLOB column (NB Db2 doesn’t have a dedicated JSON data type unlike MySQL and some other products).

And the data is successfully stored and can be retrieved and processed using other inbuilt JSON functionality (again; more of that later).
Getting the data in (more complicated)
So, my second data source is my Fitbit data (you know the one: gathers data on your activity, steps, calories burnt etc., via a gizmo on your wrist. Other wearable technology products are also available).
It’s ‘real’ data and contains a degree of complexity that didn’t exist in my little LogBook example. Here’s a snippet of the first few rows of data as exported from the Fitbit dashboard.
(I don’t think I’m giving anything away here; it’s my data, recorded by me, based on my activity. If anyone really wants to exploit this by working out how much time I spend on a bike; fill your boots.)
The structure now takes advantage of all the JSON object components:
- The data are in name/value pairs.
- Data objects are separated by commas.
- Curly braces {} hold objects.
- Square brackets [] hold arrays.
- Each data element is enclosed with quotes “” if it is a character, or without quotes if it is a numeric value.
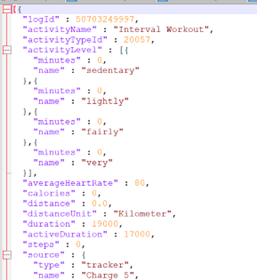
The problem now is that it spans multiple lines. And Db2 won’t cope with trying to LOAD or IMPORT that.
There are probably many ways of dealing with this but the simplest available to me seemed to be to use a Jupyter Notebook. My good friend and colleague James Gill (who, despite being a mainframe bod is an all-round good egg and a huge fund of knowledge about all aspects of technology, not just Jurassic databases) put together a nice simple piece of code to do exactly this (here’s the guts of it):

The thing with data exported from Fitbit is that, if you request all your data, you get it in 100 object chunks: each a separate file. So, the important points about that Python code are
- It opens the output file in ‘over-write’ mode
- It takes the first file and uses load and json.dumps functions to turn all the multi-row object details into a single row per object
- It then shuts the output file and reopens it in ‘append’ mode
- It will then loop through all remaining files, using the same processing to turn multi-row objects into single lines
That can be successfully Imported into a CLOB in a very similar manner to my simple LogBook example.
Conclusion
That is probably enough for one blog. That has got a volume of JSON data stored in my Db2 database and the next thing to do is to process and analyse it. I’ll do that in the next blog and then, all being well, I’m hoping to go over the same ground but show what MySQL can do by way of comparison.
If anyone has any comments or insights (i.e., if you know of better ways of doing this), please get in touch via the Triton website or by email at mark.gillis@triton.co.uk