
In the first part of this blog, I was looking at how to get your JSON data into Db2. The next bit is what to do with it. Initially, my requirement is to process the relatively complex (read “flexible”) JSON data into something simple and readable.
The data in question is taken from my Fitbit device and includes dozens of value pairs, arrays, etc. most of which I’m not that interested in. What I want to see is a simple table (and/or graph) showing how I’m doing week-by-week, or month-by-month.
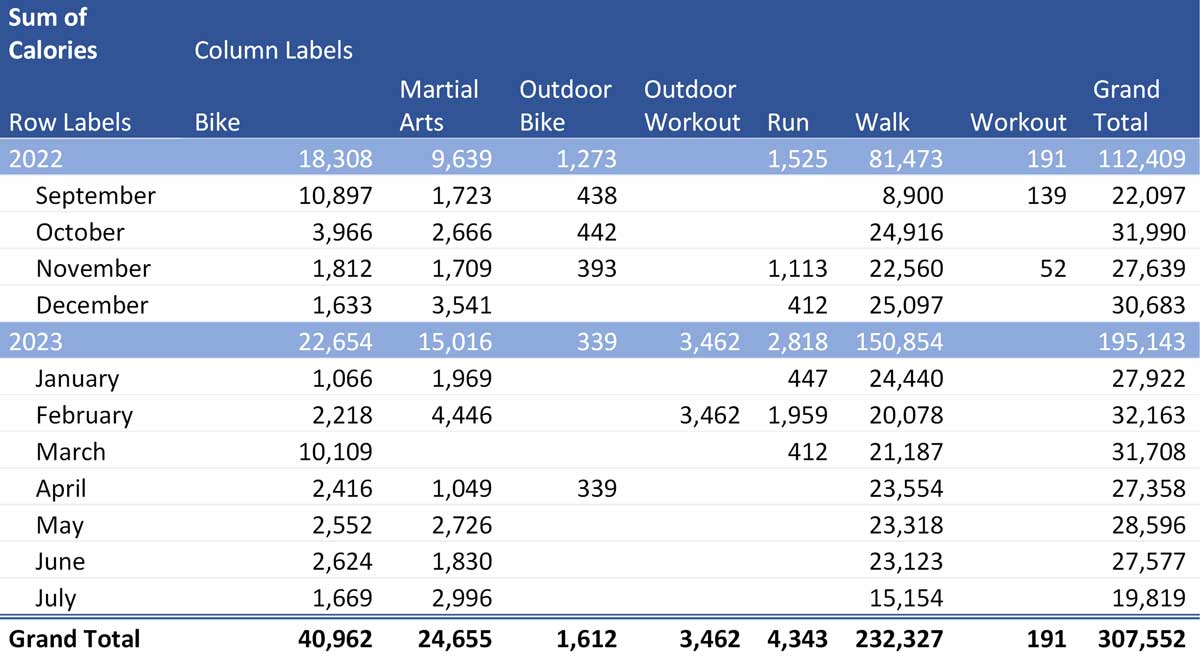
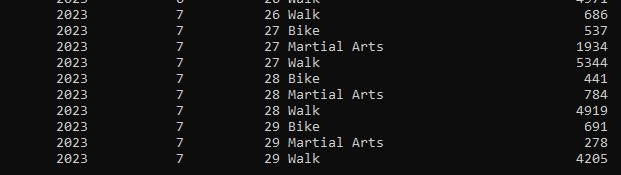
I want to end up with this:
Getting the data out
The function that I’d reach for initially is JSON_VALUE (it’s in the SYSIBM schema so you shouldn’t need any prefixing):

Which will return a result set that looks pretty much like relational data.

But I could get the same results using JSON_TABLE:
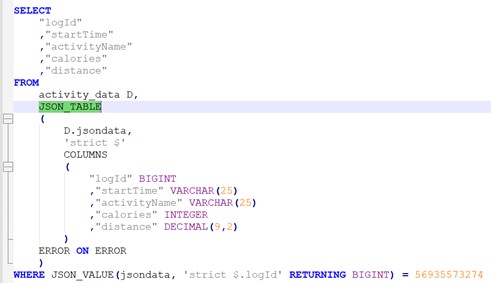
I tend to use JSON_VALUE but it’s six of one, half a dozen of the other.
More of an issue is the formatting. The Start Time is returned in an MM/DD/YY HH:MM:SS format, which is not what I want at all. Partly for readability and partly for the ability to use the dates and times in SQL operations, I want that reformatted.
The easiest and, arguably, best way of dealing with this reformatting issue is to add some extra columns to the table (or store them elsewhere, but I find adjacent is more performant; it just cuts down on the subsequent joining).
So, I added a column for the Date and Time that the activity started, and a Duration calculation.

Then I can run an UPDATE statement right after my IMPORT has been completed. It’s a bit of a monster, which is one reason why I would rather have it defined just once, as opposed to having to put this syntax in every piece of SQL that references the JSON data.
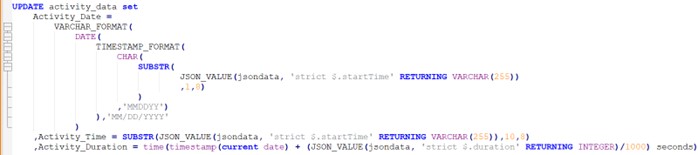
That has:
- Extracted from the character string that holds the startTime in JSON into a Db2 column defined as DATE and holding the value as MM/DD/YYYY
- Used a SUBSTR to take that part of startTime which is just the time (i.e., the last 8 characters) and store that as a TIME column
- Taken the duration value stored as Milliseconds and formatted it as a TIME column
This means that my query can now avoid the complicated syntax around retrieving the JSON value and reformatting it and can use some Db2 specific functions. A simple query can now reference the associated relational data instead of going via JSON_VALUE and doing the complicated reformatting every time. I can also get my Activity Date in UK format.
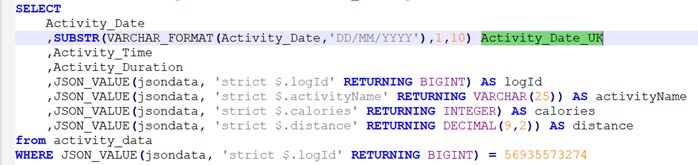
![]()
And that means I can do some dicing and slicing using Db2 inbuilt functions to get that data that I showed in the intro.

BSON
BSON data is Binary JSON storage. It’s used to store the JSON data in a more compressed format, so (possibly, sometimes; not always) saving some space but its main advantage is that allows more efficient traversal of fields and values. So, you might want to use this if query performance is critical but you might also need it for updating JSON, which is why I mention it here.
Changing the JSON data
Once the data is stored in Db2 and you’ve started to analyse and process it, you might want to change it.
But, if you really do need to change the content of the JSON object, you need to go through quite a convoluted process. Basically, you can only update BSON data and that means using the SYSTOOLS JSON functions, rather than the SYSIBM functions introduced in v11.1 Fix Pack 4. This appears to be for historical reasons and our friend and technical guru George Baklarz, from the IBM Toronto lab, told me.
“The history of the SYSTOOLs functions is that they were built for the Mongo API compatibility that Db2 provides. These weren’t based on the standard (since it wasn’t finalized yet) so that’s why they differ from the new JSON functions.”
But it leaves us with an interesting anomaly: if you want to UPDATE the JSON data, you have to use a JSON_UPDATE function that only works on BSON data. So, you need to convert the JSON to BSON, update it and then convert it back. You can do that in a single statement like this.

- JSON2BSON converts the JSON to BSON
- JSON_UPDATE changes the value of the activityName value pair, and then
- BSON2JSON converts it back to JSON
- UPDATE changes the value
A bit cumbersome but it all works in a single statement. I think the issue with this is that you might be able to persuade a DBA to build SQL like that but if I give this to a developer, they’re going to have an embolism. And imagine trying to get this sort of syntax into some of the code generating software that hurls SQL at our databases.
But would you want to update the JSON data? The conventional wisdom of a database design would suggest that any table (column, data store; whatever) should be able to be subjected to INSERT, UPDATE or DELETE but I don’t think that is what JSON is offering us. It’s a data source to be stored in Db2 and then diced and sliced using the relational functionality that is embedded in the database functionality. Updating it is probably not part of the equation.
If you want to generate JSON data from your relational data, you’d alter the source data and then generate the JSON using JSON_OBJECT or some of the other Db2 JSON Functions.
Conclusion
I think I originally approached this in the wrong way; I was trying to make JSON usable in exactly the same way as I would my other relational data. That was what my experience with XML gave me; the ability to natively store XML documents and then to digest and analyse that data with XMLQuery and xQuery. I could write pretty conventional SQL using XML functions and that gave me all the IUD functionality I needed as well as the simple SELECT options.
I don’t think JSON storage is in quite the same space. Its value is in providing a means of exchanging data, in a very open, simple and human readable format. You can parse it and analyse the data, and you can take your own relational data and produce JSON objects. But I don’t think we’re meant to tinker with data once it’s in Db2.
It’s just an opinion; I’m happy to debate the issue.
My thanks again to George Baklarz for his help with this subject and please take a look at the book he and Paul Bird produced for more details.
My plan now is to go through the same processes and use the same data but do it in MySQL. Let’s see how that goes.
email me at mark.gillis@triton.co.uk if you have any questions or observations.