

Table (or Range) Partitioning has been around since DB2 V9.7. It’s a canny option and a useful tool from both a performance and a data archiving point of view, but we do occasionally see it mis-managed and then it can be more of a nuisance than a benefit.
Overview
Partitioned tables are organized into multiple storage objects according to a key, or set of keys, defined in the CREATE TABLE statement. The following snippet
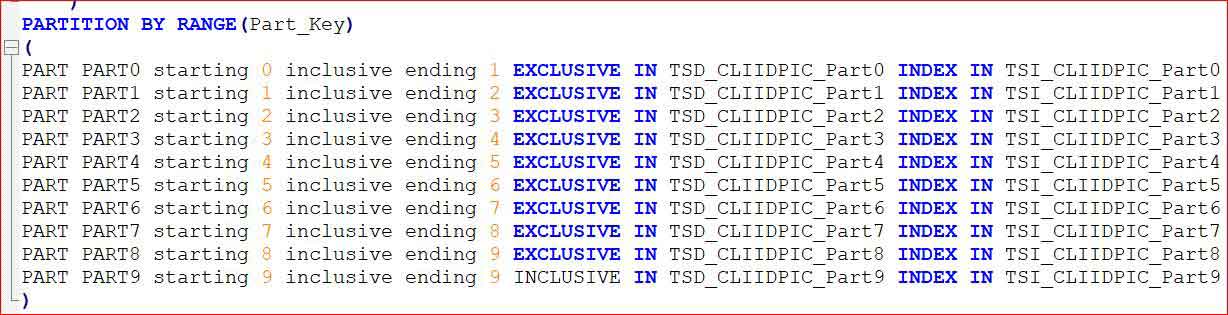
pre-defines a set of 10 partitions that will accommodate all values. It also houses the data for each partition in a discrete tablespace and the indexes for each partitioned index in a discrete tablespace (it does the same for the Large Objects, but I’ve omitted these to keep things simple). This can be driven by an existing key, or one that has been added to provide a value for the partitioning, or a value derived from a value, e.g.
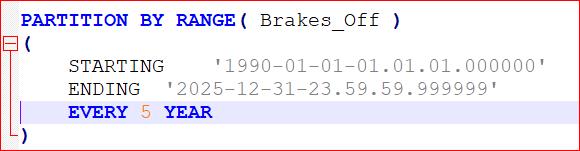
There are a large range of options for setting up the partitioned table, but that’s not the point of this discussion. What I’m hoping to look at are the benefits (the Good), the gotchas (the Bad) and where it can go seriously wrong (the Ugly).
Conversion and Implementation
Probably the best way to convert your non-partitioned table into a partitioned one, is to use ADMIN MOVE TABLE. You can either embed all the necessary options into a call to ADMIN_MOVE_TABLE, or pre-define your partitioned table and just use ADMIN_MOVE_TABLE to migrate the data over. Either way, you can keep your data on-line and thereby minimize the impact on your customers applications (Good).
Rolling In and Rolling Out (Add, Attach and Detach partitions)
Attach and Detach Partition options are advertised as being almost (almost) 0 impact. This is marvellous as, if you can identify a portion of data as being redundant, you can detach it from the table and it is immediately invisible to any queries (Good).
It does, however, have an overhead in that Asynchronous index cleanup (AIC) operations will be started if there are any non-partitioned indexes on that table. This does run in the background and won’t impede any queries but you need to be careful about gathering stats and rebinding packages: you’ll probably want all AIC operations to finish before you go ahead with any of this further housekeeping. Otherwise you might do a RUNSTATS on the table and its indexes to allow the optimizer to see what the effect of removing this partition (or partitions) of data has done, then REBIND a package and the optimizer will see the Index that is still subject to an AIC operation as unavailable and exclude it from your access path (Bad).
Of course, you can avoid this if all the indexes on the table are defined as Partitioned and that is something to consider as part of your migration to a Partitioned solution.
The Add Partition operation is genuinely 0 impact; if you run a command like this
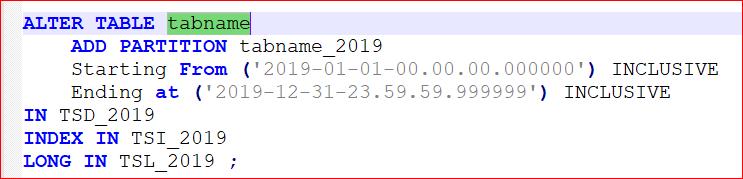
theres a new partition waiting there, right away, ready to accept the data for this year (Good).
However, this partition has been defined to use new and explicit tablespaces for its data, indexes and LOBs. This is good practice but if you create these new tablespaces as part of your regular Partition housekeeping and you use Incremental Backup, then you need to take a BACKUP of each of the new tablespaces, even though they’re empty, to avoid invalidating your incremental images (Bad).
The Attach option lets you put a previously defined and, maybe, populated partition into the table. It’s very useful if you want to return a partition that has previously been Detached and, again, very little impact if you can avoid non-partitioned indexes (Good).
Performance
Now this is going to be Stating The Obvious but… you do have to get your partitioning keys right. Although the ability to DETACH a portion of your data and immediately remove it from the application is useful if you have that archiving requirement, we find that the driver for the use of partitioning is usually more about performance. If you get the partition key definition right and it matches the WHERE clauses that your queries use, then you’ll get this sort of thing in your db2expln output:
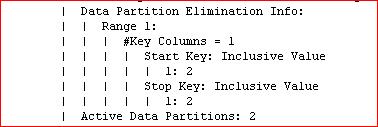
This is Good as it will be allowing the query to just concentrate on a subset of the data. However, if you have a query accessing a partitioned table and you’re seeing this
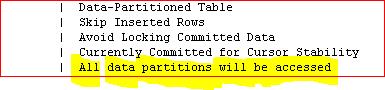
That’s clearly got to be Bad. Your query is going to scan right across the table and all it’s partitions. It might allow some parallelism but it’s not going to be as efficient as Partition Elimination.
One of the problems with a mis-defined partitioned table is that it is not going to be easy to get it migrated over to the correct partitioning design. ADMIN_MOVE_TABLE isn’t going to be able to help because
“Only simple tables are supported as the source table. No materialized query tables, typed tables, range clustered tables, system tables, views, nicknames, or aliases are permitted”
So, if you don’t get your partitioning design right first time around, you are probably going to have to take the data off-line to convert it (Ugly).
I’m in the middle of some work for a customer who has exactly this situation. A number of crucial tables have been converted to Partitioned and the chosen key was the Year of the creation date, which is handily defined on all tables. The trouble is a) the business in question cannot archive data based on when it was created. There is a very complex business requirement around the data and it might only be possible to identify data to archive by referencing values other than dates. Also, b) none of the queries ever makes use of this column, so there’s no partition elimination (Bad).
Because ADMIN_MOVE_TABLE can’t help us, I’m having to pre-define a new table partitioned on the data that the analysts have specified, then LOCK the table, do a LOAD FROM CURSOR and then a RENAME to swap the new table for the old table name. In some cases, this is going to mean taking critical data off-line for over 6 hours (Ugly).
Conclusion
So, in conclusion, I’d say that table partitioning is a brilliant option; it can give you definite performance advantages and allows carefree handling of data archiving. If you get your definitions right and you get them right first time. So it’s up to you whether you end up with a cool, hard-eyed gunslinger of a solution, or a mean, shifty and untrustworthy killer (if you still don’t recognize the allusion; shame on you and go see this The Good, the Bad and the Ugly).
If in doubt, contact Mark Gillis, Principal Consultant at Triton Consulting
E-mail: Mark.Gillis@triton.co.uk
Mobile: +44 (0)7786 624704
 About: Mark Gillis – Principal Consultant
About: Mark Gillis – Principal Consultant
Favourite topics – Performance Tuning, BLU acceleration, Flying, Martial Arts & Cooking
Mark, our kilt-wearing, karate-kicking DB2 expert has been in IT for 30+years (started very young!) and using DB2 for 20+. He has worked on multi-terabyte international data warehouses and single-user application databases, and most enterprise solutions in between.
During his career Mark has adopted roles outside of the conventional DBA spectrum; such as designing reporting suites for Public Sector users using ETL and BI tools to integrate DB2 and other RDMS data. He has worked extensively in the UK, but also in Europe and Australia, in diverse industry sectors such as Banking, Retail, Insurance, Petro-Chemicals, Public Sector and Airlines.
Currently the focus of Mark’s work is in Cloud migration and support, hybrid database enablement and providing expertise in exploiting the features and functions of Db2 V11.1 and 11.5.
View Mark’s blogs and tech tips.