

This should be pretty straight-forward: you can look in the TABLES System Catalogue and find references for the data (TBSPACE), Indexes (INDEX_TBSPACE) and Large Objects (LONG_TBSPACE). But DB2 throws a few curved balls here; partitioned tables (where the data, indexes and LOBs can be in multiple tablespaces), particular types of index that don’t seem to be in the catalogues at first glance, etc. Let’s see if we can put something together that shows the complete picture.
Overview
I’ve got a little database with all sorts of weird and wacky objects. It’s tiny, in terms of volume, but includes row and column-organized tables, range-partitioned tables, MQTs and a bunch of other stuff. Some tables have the full “INDEX IN … LONG IN ….” Tablespace definitions but don’t actually use them, some don’t have any or all the tablespace directives. I want to be able to see the full picture, so how do I go about that?
Well here’s the output from the basic query against SYSCAT.TABLES, for 7 of my tables in the LOGBOOK schema.
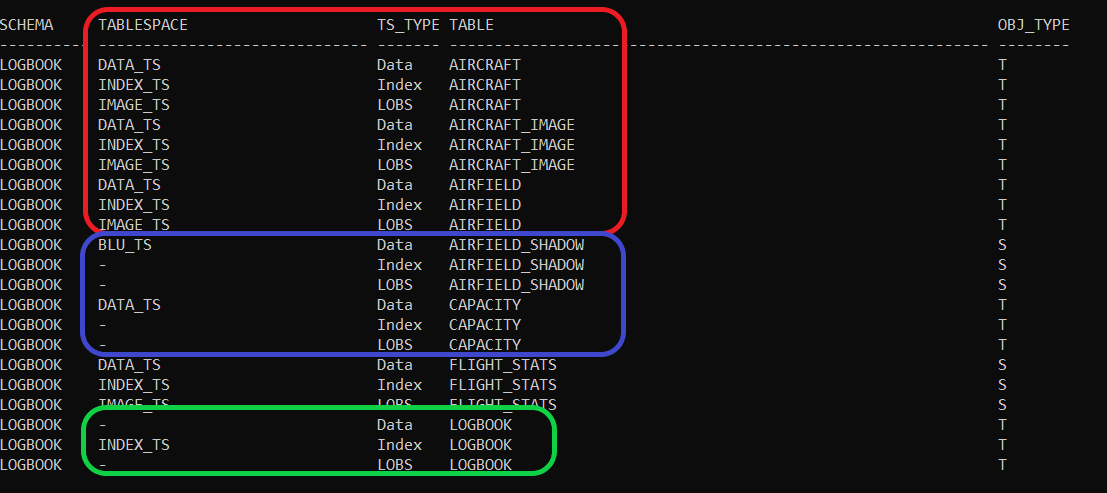
(The Object Type is either T for Table or S for Summary Table at this stage)
The first 3 tables, highlighted with the red outline; AIRCRAFT, AIRCRAFT_IMAGE and AIRFIELD, appear as we might expect, with their Data in DATA_TS, Indexes in INDEX_TS and LOBS in IMAGE_TS. Except… they’re not. The AIRCRAFT table was defined like that (see below) but note that there is no column defined as a large object.
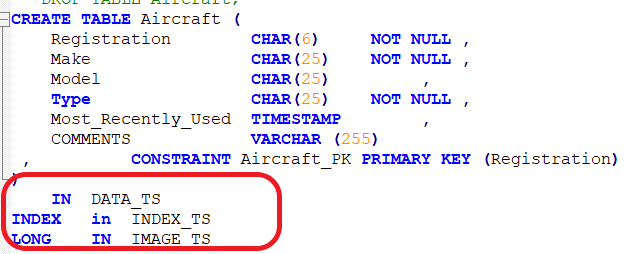
So, this query is showing where that data would go if I altered the table, but not where it actually is.
The next 2 tables in Figure 1 (blue outline) only have a Data tablespace. That’s OK, but I don’t need to see those NULL values; I’m only interested in where data is, not where it isn’t.
And the last table (LOGBOOK; green outline) is mighty confusing; it only has an Index tablespace and no data. So, what is going on here?
Partitions
Starting at the bottom and working up: that LOGBOOK table is a range-partitioned object, so it includes this in its definition:
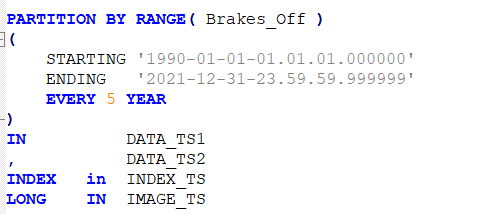
Hence there will be 5 years’ worth of data in DATA_TS1, then the next 5 years in DATA_TS2, then the next 5 in DATA_TS1 again, and so on and so on. But you can’t show that in SYSCAT.TABLES because there is only one column for the Data Tablespace: TBSPACE. So, you need to get some data from SYSCAT.DATAPARTITIONS and you want the existing query, (the bit that isn’t looking at Partitions), to exclude any partitioned objects. The best way of doing that, IMHO, is to have a WITH clause like this

You need that HAVING COUNT option because the DATAPARTITIONS catalogue will also include data for non-partitioned tables. AIRCRAFT, for instance, despite not being partitioned, has a single row in DATAPARTITIONS with a Partition Name of PART0.
I can now use that Common Table Expression, or WITH clause, to eliminate any partitioned tables from the first half of the query. And I can write a second half (UNION is involved) to examine DATAPARTITIONS and INDEXPARTITIONS for the details on LOGBOOK, or any other partitioned table. The output for LOGBOOK now looks like this

Although, you will have noticed I’m sure, that we have an index in INDEX_TS and some indexes in DATA_TS1 and DATA_TS2. That is because a non-partitioned index will go into the tablespace defined with the INDEX IN clause in the CREATE TABLE, but the partitioned index will reside with the data to which it relates (unless you include a specific INDEX IN clause in the partition definition). So, this is good; it’s showing me a bit more of what I want to see; exactly where my data (which includes index entries) actually is.
Only single Tablespace definition
The next issue is the CAPACITY table, and other tables defined in a similar fashion.

The definition included an INDEX IN … and LONG IN … when the table was created, but there are no indexes or LOBs. So, we put a couple of extra bits into the query, to make sure that there is some content in those tablespaces. We can have this for indexes
EXISTS (SELECT * FROM SYSCAT.INDEXES I WHERE I.TabName=T.TabName)
And this for LOBS (NB: these are from separate sub-queries that are UNIONed together)
EXISTS (select CHAR(TabName,10) table, CHAR(colname,12) Column
from SYSCAT.COLUMNS C
WHERE C.TabSchema=T.TabSchema AND C.TabName=T.TabName
AND typename in (‘BLOB’,’CLOB’,’XML’))
But this only eliminates the null row for the large object tablespace. Further investigation needed…

Missing Indexes
CAPACITY is a tiny reference table, so it doesn’t merit any tablespace definition for indexes. It only has a reference to DATA_TS in the table CREATE statement, so any indexes will have gone in there.

If you look in SYSCAT.TABLES, the other tablespace values are null, but if you check for the existence of indexes, it has got a Primary Key.
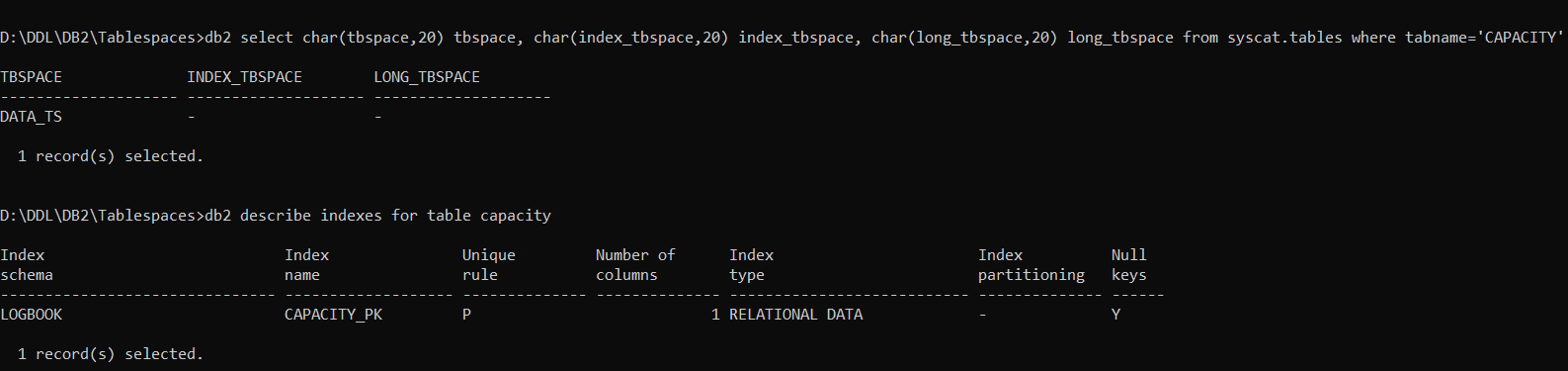
This means that the sub-query for Indexes cannot be driven from SYSCAT.TABLES; it has to come from SYSCAT.INDEXES. Once that modification is done, the output begins to look a bit more like it
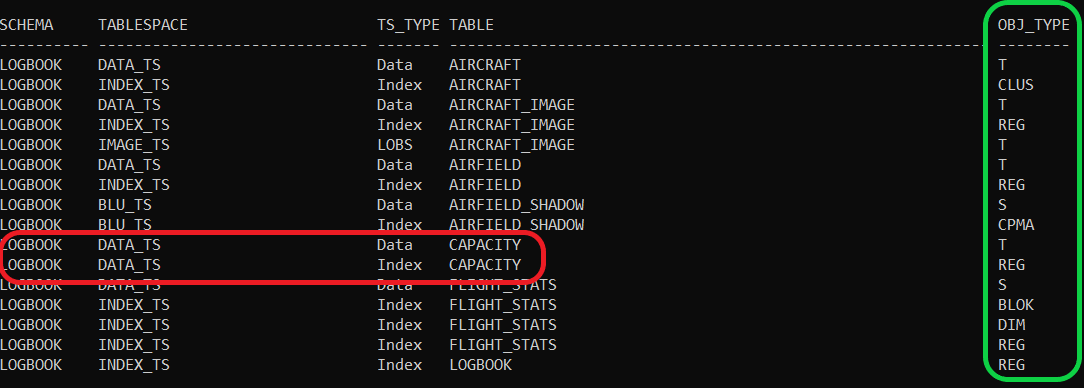
(The Object Type now includes the Index types:
| CLUS | Clustering |
| REG | Regular |
| CPMA | Column Page Map |
| BLOK | Block |
| DIM | Dimension |
(More detail on these below)
CAPACITY is now showing up as having its Index resident in the DATA_TS tablespace and, as an added bonus, the object types in the last, green-outline column, can now include a relevant index type. You can see Block and Dimension index entries associated with FLIGHT_STATS. This is a Multi-Dimensional Cluster and, if you go back to the original display as Fig.1, you’ll see there wasn’t much detail; just a single row saying all indexes were in INDEX_TS. Which they are; but this gives a bit more depth to that data and shows where the index data is and for what purpose.
Column-Organized Tables
Similarly, the original Fig.1 display showed that the AIRFIELD_SHADOW table had no data available with respect to indexes. This is because it is a shadow copy defined to use a single tablespace configured for Columnar data (see Shadow Tables blog or Shadow Tables eBook for some details on Shadow Tables, if you’re not familiar).
Shadow tables are column-organized, so always have a system generated CPMA index. This is a page-map index and is generated by the system; there will be one for every column-organized table whether you like it or not. You can either specify some INDEX IN definitions in your table definition or let it default to the single tablespace (and I think the jury is still out on this one) but, in this example, the CPMA index has been built in the default BLU_TS tablespace and the query needs to get the details from SYSCAT.INDEX to show this.
The other thing a column-organized table will have is a system-generated Synopsis table (see those links in the earlier paragraph for details). A synopsis table is, itself, a column-organized table and will therefore also have a CPMA index, so we want this to be visible too. This will mean another Common-Table Expression or WITH clause in this query to identify Synopsis Tables associated with any nominated Column-Organized tables. This is the code fragment

And our output now looks like this
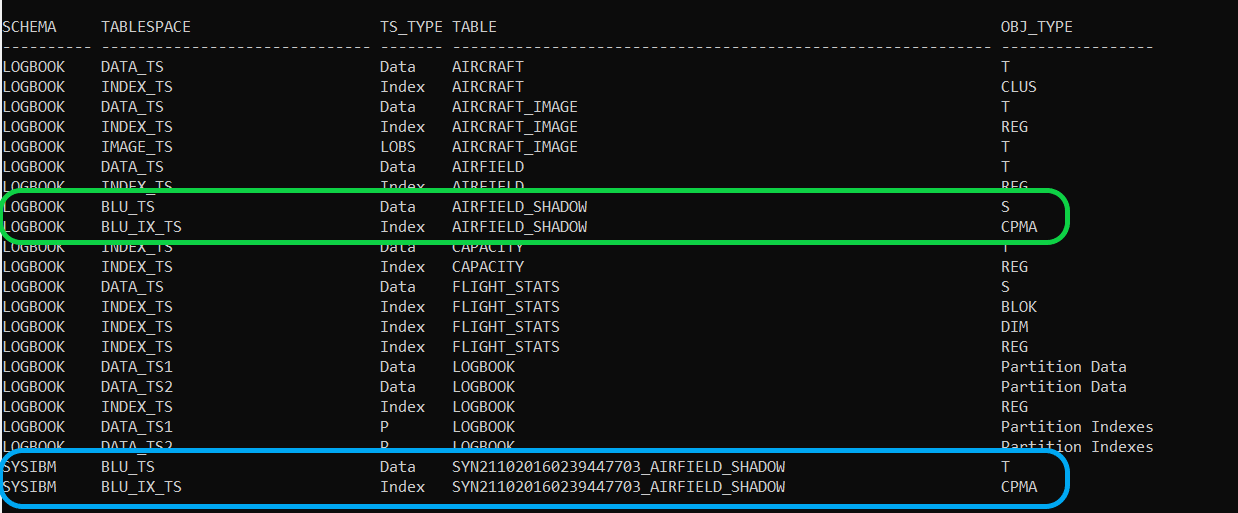
The green outline is the Shadow table and it’s CPMA index (note the Object Type is ‘S’ for Summary) and the turquoise outline is the automatically created Synopsis table, and it’s CPMA index. The synopsis is not a Summary table; it’s a ‘regular’ column-organized table.
“Misplaced” objects
By which I mean, the objects in question have ended up in a tablespace where you wouldn’t expect them. For instance, I will rebuild the CAPACITY table with no specified tablespaces. If I re-run my query, you can now see that the Data and the Index for CAPACITY is in the INDEX_TS.

This is because, in the absence of any definition from my CREATE statement, the table has been created in the default tablespace. This isn’t as straightforward as it might seem; there is no flag you can set to say “make this tablespace the default”. There is a list of criteria in the CREATE TABLE section of the Knowledge Centre (https://www.ibm.com/docs/en/db2/11.5?topic=statements-create-table ) but the bottom line is
“If more than one table space still qualifies, the final choice is made by the database manager”
So, you can’t be entirely sure where it will end up. Best to put in a specific definition.
Conclusion
What we’ve ended up with is a single query that should show all your data placement (and I include index entries in that). It should show all the objects for a specified schema and/or set of tables, omit any tablespace entries that are empty and include any dependent objects.
It’s not an entirely exhaustive query; there are too many options, features and gizmos in DB2 to trap all of them. But it covers a lot of the options.
You can drive it by Schema, Table name(s) or Tablespace. I’ve tested it in a number of different environments and, whilst I can’t guarantee it bullet-proof, it’s proved very useful to me in my day-to-day work.
Please contact me if you’d like me to share any of the code referred to in this blog although, please bear in mind, it’s supplied on a purely “as-is”, unsupported basis. That said, if anyone has insights of their own, or scenarios that you don’t think this covers; I’d be happy to hear about them. You can email me here.