

Introduction
In the previous blogs in this series, we’ve run through installing IBM Open Enterprise Python for z/OS and IBM z/OS Open Automation (ZOA) Utilities, which are the required pre-requisites for Ansible to perform actions on z/OS. In the third of this series, we will look at the installation of Ansible on Linux and an example playbook execution of Ansible to gather simple information and perform some tasks.
Architecture
In this example, we will be working with a control node – where the ansible script (playbook) will execute – and one or more z/OS hosts which will be the target(s). In this case the control node will be on Linux. Note that connectivity is via SSH, which needs to be configured and available for the userids that will be used on the target z/OS hosts.
Reference Documentation
General Ansible documentation https://docs.ansible.com/ansible/latest/index.html
Galaxy documentation https://docs.ansible.com/ansible/latest/galaxy/user_guide.html
Ansible content for IBM Z https://ibm.github.io/z_ansible_collections_doc/index.html
Installing Ansible
Using Internet Access
If you have direct internet access from the server that you’re going to install on, then as root, use the Python pip3 installer:
pip3 download ansible
This should gather the following packages:
- ansible-base
- Jinja2
- MarkupSafe
- packaging
- pyparsing
- PyYAML
Once binary uploaded, they can be installed with:
pip3 install ansible –find-links ./
This will produce warning messages as it initially attempts to pull the packages from the internet, before searching the local path (current directory).
Verifying the Installation
Once the install has completed, verify with:
zpdt@alexander:~>; ansible --version
ansible 2.10.6
config file = /home/zpdt/ansible.cfg
configured module search path = ['/home/zpdt/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python3.6/site-packages/ansible
executable location = /usr/bin/ansible
python version = 3.6.12 (default, Dec 02 2020, 09:44:23) [GCC]
Installing z/OS Collections
To support interacting with z/OS, a number of collections have been written and delivered via GitHub and Ansible Galaxy. The ones available at the time of writing are:
- ibm_zos_core – this is the base collection and includes job handling (submit, track, etc), dataset handling, etc. It is the base set and is required.
-
ansible-galaxy collection install ibm.ibm_zos_core
-
- ibm_zos_zosmf – provides zOSMF REST interface action support in ansible. E.g. workflow services, job and console support.
-
ansible-galaxy collection install ibm.ibm_zos_zosmf
-
- ibm_zos_ims – provide support for generating DBDs, PSBs and ACBs as well as issuing type 1 and type 2 IMS commands
-
ansible-galaxy collection install ibm.ibm_zos_ims
-
- ibm_zos_sysauto – provides support for Z Systems Automation REST server interface actions
-
ansible-galaxy collection install ibm.ibm_zos_sysauto
-
We will concentrate on the first one – ibm_zos_core – as this is required for all of the others and provides general application build / install / management support. This was installed on Linux using:
ansible-galaxy collection install ibm.ibm_zos_core
zpdt@alexander:~> ansible-galaxy collection install ibm.ibm_zos_core
Starting galaxy collection install process
Process install dependency map
Starting collection install process
Installing 'ibm.ibm_zos_core:1.2.1' to '/home/zpdt/.ansible/collections/ansible_collections/ibm/ibm_zos_core'
Downloading https://galaxy.ansible.com/download/ibm-ibm_zos_core-1.2.1.tar.gz to /home/zpdt/.ansible/tmp/ansible-local-146210wvhqtyv/tmpu0n0pw84
ibm.ibm_zos_core (1.2.1) was installed successfully
Verify the installation with:
ansible-galaxy collection list
There is a big list of centrally installed collections (delivered as part of ansible), and then the local user entries
zpdt@alexander:~> ansible-galaxy collection list
# /usr/lib/python3.6/site-packages/ansible_collections
Collection Version
----------------------------- -------
amazon.aws 1.3.0
ansible.netcommon 1.5.0
ansible.posix 1.1.1
:
vyos.vyos 1.1.1
wti.remote 1.0.1
# /home/zpdt/.ansible/collections/ansible_collections
Collection Version
---------------- -------
ibm.ibm_zos_core 1.2.1
To install the collection centrally, you’ll need to set the ANSIBLE_ROLES_PATH environment variable – e.g.
export ANSIBLE_ROLES_PATH= /usr/lib/python3.6/site-packages/ansible_collections;~/.ansible/collections/ansible_collections
The ansible-galaxy installer will install the collection / role in the first writable path in the list. As we are using a non-root user, this has installed a local copy.
Configuration
Configuration File
Ansible is configured by entries in a configuration file. This is located by looking through the following until one is found:
- ANSIBLE_CONFIG environment variable exists and points to a file
- cfg in the current directory
- .ansible.cfg in the home directory
- /etc/ansible/ansible.cfg
In most cases, the defaults are fine. The default for the number of parallel hosts being processed is set very low (5) in the “forks” parameter and this should be raised. Ansible also recommends turning on ssh connection pipelining as it provides a performance benefit, although for compatibility with the sudoers requiretty option, it is disabled by default. These can be updated and enabled by adding the following to your configuration file:
[defaults]
forks = 25
[ssh_connection]
pipelining = True
In our example we were originally using the home directory for user zpdt to work from, and had a configuration file (ansible.cfg) there – see the “ansible –version” output in the installation section, above. This is actually a bit lazy and could lead to confusion later, so this has been renamed to “.ansible.cfg” so that it sets the configuration for the user, regardless of where the playbook is run from.
When we run an Ansible script, we pass it a list of hosts to work with. This is called the inventory file and we can set a default location for this in the config [defaults] section as well:
inventory = /home/zpdt/inventory.yml
Inventory File
As mentioned above, this is the file that is passed to ansible to inform it about all of the potential hosts to operate on. This can be in a number of different styles (INI, YAML, etc). In the examples we are going to focus on YAML, e.g.
source_systems:
source_systems:
hosts:
zos_host:
ansible_communication: ssh
ansible_host: 192.168.2.25
ansible_user: ibmuser
ansible_python_interpreter: /usr/lpp/IBM/cyp/v3r8/pyz/bin/python3
There is much more that can be done with inventory files, including server groupings and host and group variables – have a dig in the Ansible documentation for more on this.
Connection Security
It’s worth covering this before going into some example playbooks. The connectivity method that we are using here is SSH. This can be run by setting a password in the inventory file for each host or by setting up passwordless SSH connectivity using shared keys. The first of these is a maintenance and security disaster, and only covers the connection itself. This means that if you copy a file to z/OS, Ansible uses the secure copy command under the covers, and you will be prompted for the password anyway. With only a single ZPDT z/OS in our configuration, we could just edit the password every time it changes, but what if your inventory has 70 LPARs to manage? And there is a bit of a security risk exposing the passwords for that many services in a single file.
The better option is to use the shared keys SSH method. This works by generating a key for the userid on Linux that will run the playbook, then applying this to the z/OS user that will be used to perform the actions. As you can see in the inventory file, I’ve used the IBMUSER account to connect and (by default) perform actions with. To setup the passwordless / shared keys connection:
- On Linux, with the Ansible playbook execution user (zpdt), create the SSH keys using ssh-keygen:
ssh-keygen -t rsa -b 4096 -C zpdt@alexander.zpdt.local- When prompted for a passphrase, bypass this with Enter (a blank) – otherwise you will be prompted for it every time the key is used
- Note the -C (comment) option – this is necessary to support management of the shared keys on z/OS and allows a keys owner to be easily identified if, for example, you want to remove a users access
- Still on Linux, apply the resulting public key to the target user (ibmuser) authorized keys file:
ssh-copy-id ibmuser@192.168.2.25- Note that you will be prompted for the target userid password for the copy if the local Linux user isn’t already in the authorized keys file. If it is, the copy will be bypassed to avoid duplicate entries
- Test the connectivity from Linux by trying to connect with SSH and see if you are prompted
Some example output:
zpdt@alexander:~> ssh-copy-id ibmuser@192.168.2.25
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/zpdt/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
ibmuser@192.168.2.25's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'ibmuser@192.168.2.25'"
and check to make sure that only the key(s) you wanted were added.
zpdt@alexander:~> ssh ibmuser@192.168.2.25
IBMUSER:/u/ibmuser: >
Note that the ssh-copy-id prompts for the ibmuser password, but the ssh does not.
An Example – Run a Sample DB2 for z/OS Batch IVP
The IVP – initial verification procedure – is typically run after maintenance is delivered to a service to check that basic function is okay. This includes jobs to reset the sample environment, create objects and build and run sample applications. The IVP jobs are built by the DB2 installation CLIST as part of the environment tailoring with the original installation of a subsystem. Parameters to this Ansible playbook will be:
-
-
- JCL library holding the jobs
-
Using host variables – values configured for a specific host – makes this fairly simple. The directory structure in our test case looks like this:
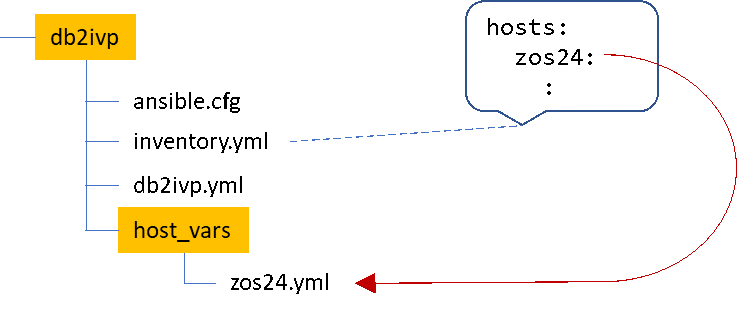
Our sample inventory.yml file looks like this:
all:
hosts:
zos24:
ansible_host: 192.168.2.25
ansible_communication: ssh
ansible_user: ibmuser
ansible_python_interpreter: /usr/lpp/IBM/cyp/v3r8/pyz/bin/python3
Note that we only have the one host defined (our zPDT) called zos24.
In the host_vars subdirectory we have zos24.yml, which is the variables to use specifically for this host. It looks like this:
# the path to the root of IBM python installation
PYZ: "/usr/lpp/IBM/cyp/v3r8/pyz"
# the path to root of ZOAU installation
ZOAU: "/usr/lpp/IBM/zoautil"
# you should not need to change environment_vars
environment_vars:
_BPXK_AUTOCVT: "ON"
ZOAU_HOME: "{{ ZOAU }}"
PYTHONPATH: "{{ ZOAU }}/lib"
LIBPATH: "{{ ZOAU }}/lib:{{ PYZ }}/lib:/lib:/usr/lib:."
PATH: "{{ ZOAU }}/bin:{{ PYZ }}/bin:/bin:/var/bin"
_CEE_RUNOPTS: "FILETAG(AUTOCVT,AUTOTAG) POSIX(ON)"
_TAG_REDIR_ERR: "txt"
_TAG_REDIR_IN: "txt"
_TAG_REDIR_OUT: "txt"
LANG: "C"
# DB2 IVP JCL PDS
db2ivp_pds: "SDB2T.DSNTID00.SDSNSAMP"Note the last line, which defines the db2ivp_pds variable, which we’ll use in the playbook:
---
# perform a DB2 IVP
#
- hosts: all
collections:
- ibm.ibm_zos_core
gather_facts: no
environment: "{{ environment_vars }}"
connection: ibm.ibm_zos_core.zos_ssh
vars:
m1: "{{ 'From : '+db2ivp_pds }}"
tasks:
- name: "Playbook start timestamp"
debug:
msg="{{ lookup('pipe','date') }}"
- name: "Submitting DB2 IVP jobs"
debug:
msg="{{ m1 }}"
- name: "Submit the jobs"
zos_job_submit:
src: "{{ db2ivp_pds }}({{ item.name }})"
location: DATA_SET
wait: true
max_rc: "{{ item.maxrc }}"
with_items:
- { name: "DSNTEJ0", maxrc: 8, comment: "reset the IVP db elements" }
- { name: "DSNTEJ1", maxrc: 4, comment: "create objects and LOAD sample data" }
- { name: "DSNTEJ1P", maxrc: 4, comment: "create and run DSNTEP2 and DSNTEP4 samples" }
- { name: "DSNTEJ1S", maxrc: 0, comment: "BIND and run the schema processor" }
- { name: "DSNTEJ1U", maxrc: 0, comment: "create and LOAD UNICODE objects" }
- { name: "DSNTEJ2A", maxrc: 4, comment: "create and run the DSNTIAUL sample assembler tool" }
- { name: "DSNTEJ2C", maxrc: 4, comment: "create and run sample COBOL batch programs" }
- { name: "DSNTEJ2D", maxrc: 4, comment: "create and run sample C batch programs" }
- { name: "DSNTEJ2E", maxrc: 4, comment: "create and run sample C++ batch programs" }
- { name: "DSNTEJ2H", maxrc: 4, comment: "create and run sample C/C++ XML programs" }
- { name: "DSNTEJ2P", maxrc: 4, comment: "create and run sample PL1 batch programs" }
- { name: "DSNTEJ2U", maxrc: 4, comment: "create and execute sample UDFs" }
- { name: "DSNTEJ3C", maxrc: 4, comment: "create COBOL / ISPF phone application" }
- { name: "DSNTEJ3P", maxrc: 4, comment: "create PL1 / ISPF phone application" }
- { name: "DSNTEJ6U", maxrc: 4, comment: "create and run app to test utilities stored proc" }
- { name: "DSNTEJ6Z", maxrc: 4, comment: "create and run app to drive ADMIN_INFO_SYSPARM proc" }
- { name: "DSNTEJ7", maxrc: 4, comment: "create sample objects to support LOB tests" }
- { name: "DSNTEJ71", maxrc: 4, comment: "apply the employee photos to the sample data" }
- name: "Playbook end timestamp"
debug:
msg="{{ lookup('pipe','date') }}"
Observations
There’s a lot to like about this solution – extending the reach of Ansible on to z/OS helps bring the platform into the DevOps world, and the software needed to run it is (currently) freeware. However, there are some key challenges that IBM will need to address:
-
-
- Shared key SSH connectivity will not necessarily be to the tastes of all large enterprise security teams. Ansible is a much lower cost alternative to Urbancode Deploy on z/OS, but the latter supports TLS connectivity using client certificates to authenticate work and requests in RACF.
- The Enterprise Python implementation has not been ZIIP enabled, which means that all of the USS based Ansible framework work runs on GCP, with charging implications for the user. In testing on a zPDT (emulated mainframe, so caveat emptor) a two job batch workload which uses 37 CPU seconds in 3 minutes when submitted by hand, took 25 minutes to run and the Ansible aspects added an additional 200 CPU seconds. This may have happened because the single CPU hit and held at 100%, which we have only previously encountered with Java workload startup.
- The offering is not yet mature. When testing the DB2 IVP script included above, an error was encountered in the Ansible framework in USS on z/OS because the output of job DSNTEJ1U includes a backslash (“”) character. It also occurred with all of the remaining jobs which compile C/C++ code where the character is used for string escape sequences and line continuation.
-
We would be interested in others experiences of the performance and CPU cost of Ansible workloads on “real” zSeries hardware. If anyone has any experience of this, please feel free to share in the feedback comments below.
Conclusions
This is an excellent idea, and it will be an excellent solution if IBM can address the challenges outlined above. Ansible has a huge following and enthusiastic worldwide development community that will embrace z/OS when this happens.
View all blogs in James Gill’s Ansible series.