

This is the fourth article in the series on locking for DB2 for z/OS developers. To summarize the main thrust of this series of articles, data integrity and application performance are dependent on application programs being designed and coded to take into account the locking strategy used by the DBMS. Following on from the previous articles, this one wraps up the discussion on lock size and lock mode with the topic of lock escalation and provides some recommendations on lock size before moving on to describe the final component of the locking mechanism covered in this series, lock duration.
If there is a large number of locks on a tablespace, that can become an issue for too many reasons to go into here, but those reasons do include the memory and CPU resource required to manage those locks. To limit those effects, DB2 provides the system administrator with two controls. Firstly, the system parameter or ZPARM NUMLKTS specifies a system-wide limit on the maximum number of locks that can be acquired on a tablespace. This is a default attribute which can be over-ridden at the tablespace level by the second control, the attribute LOCKMAX. If the number of page or row locks exceeds this value, then lock escalation occurs. With lock escalation, DB2 attempts to release the page or row locks, and then acquire tablespace gross locks to replace the intent locks. That is, DB2 attempts to replace an IX lock with an X lock, and an IS lock with an S lock.
In one way this is good, because it can improve performance by reducing the CPU cost of locking and in some specific cases can work well. On the other hand, lock escalation usually impacts the production service adversely, because it inhibits concurrency and increases the chance of lock contention, timeouts and deadlocks.
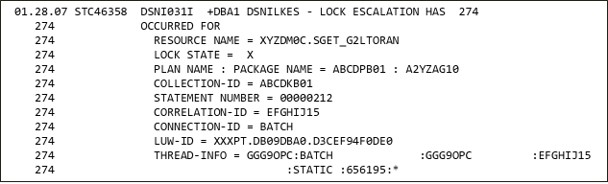
Figure 1 Lock Escalation message
Because lock escalation can be disruptive, DB2 records every occurrence in the DB2 System Services message log with message DSNI031I in the as illustrated in Figure 1 above. Many DB2 sites use automation to capture these messages and report on them so that action can be taken to avoid lock escalation.
This brings us on to some lock size recommendations:
- When coding for concurrent access to DB2 data, you should avoid LOCKSIZE TABLESPACE, as this is very likely to serialize access to the tablespace. Exclusive (X) locks definitely will, while share (S) locks allow concurrent read access but no updates.
- Use LOCKSIZE PAGE as a design default. In most cases, this will provide the best balance between locking the data for integrity reasons, transaction concurrency, CPU resource consumption and transaction performance.
- Use LOCKSIZE ROW where justified – some applications are dependent on LOCKSIZE ROW for concurrency reasons. The disadvantage with LOCKSIZE ROW is that it will increase the number of locks taken and therefore CPU overhead where many rows per page are accessed, and is more likely to lead to lock escalation than LOCKSIZE PAGE1. However, if the application only accesses one row per page, then the number of locks taken is the same with LOCKSIZE PAGE and LOCKSIZE ROW. Nevertheless, bear in mind that LOCKSIZE ROW increases the data sharing overhead – because the primary focus of this series of articles is data integrity, I won’t go into the data sharing overhead here.
- Avoid lock escalation:
- For long-running applications which update many rows, typically batch applications, commit frequently.
- Set NUMLKTS and LOCKMAX realistically to prevent lock escalation without causing unnecessary application failures.
- Avoid RR and RS isolation levels (of which more in the next article).
There are no real lock mode recommendations: for LOCKSIZE PAGE or ROW, DB2 uses the least restrictive lock mode required to guarantee data consistency/integrity in line with the transaction isolation level in effect (discussed in the next article) while enabling transaction concurrency.
This brings us onto the next characteristic of DB2 for z/OS locking: lock duration. Lock duration is important not only for concurrency but also for atomicity.
With short lock durations, there is less potential for locking conflicts between concurrent applications, and a smaller impact in terms of lock suspension times and elapsed times. Exclusive locks, taken when data is changed, must be held until the commit point. This is to comply with the atomicity principle of ACID – that is, that either all of a transaction’s updates are made to the database, or none of them are made. Before clarifying the role COMMIT plays for a transaction, let’s consider what would happen if all the changes to data made by an application were made permanent in the database for every single SQL call2.
For example, consider a business process which makes a number of SQL calls when processing a funds transfer between two bank accounts, with autocommit in effect. This requires at least two SQL calls to change the data, but probably more because of auditing, recording of historical data such as a transaction log, and so on. Imagine the worst case, a system failure part way through the business process (e.g. a subsystem abend or a power failure). When the system comes back up the data no longer has integrity. This cannot be detected by the DBMS itself, and is extremely difficult for the application or the DBA to detect and correct. The same applies to transaction abnormal terminations3.
There are two points of clarification to be made about commits. Firstly, a commit point marks the end of a logical unit of work (such as a business process) and indicates that all updates are to be made permanent in the database – the durability property. Well-behaved, long-running processes, typically batch jobs, make intermediate commits to limit the number of locks held, to improve concurrency, and to reduce the length of the backout process in the event of a failure. Secondly, a commit scope is the period between commit points (the start of the transaction can be regarded as an implicit commit point, or more accurately a point of data consistency, when talking about the commit scope).
How long are locks held? Lock duration is determined by a number of factors:
- The isolation level (discussed in the next article).
- The lock size (tablespace, partition, page, row) – what is the object that’s being locked.
- The lock mode (IS, IX, S, U, X).
- The RELEASE and CURRENDATA options of the BIND/REBIND command
- Whether or not a cursor is declared using the WITH HOLD attribute.
- When a cursor specification includes WITH HOLD, the cursor is not closed when the application issues a commit. In addition, any locks that are necessary to maintain the cursor position are held past the commit point, into the next commit scope.
With regard to lock size, lock duration for tablespaces/partitions is determined by the RELEASE option of the BIND/REBIND command, which has two options:
- RELEASE(COMMIT): with this options, tablespace and partition locks are held for the duration of the commit scope.
- RELEASE(DEALLOCATE): with this option, tablespace and partition locks can potentially be held across multiple commit scopes. The objective is to avoid the repeated CPU cost of frequently acquiring and releasing intent locks. There are two potential uses for RELEASE(DEALLOCATE):
- Batch programs with intermediate commits, as discussed earlier.
- High-volume transactions running under CICS protected entry threads, pseudo-WFI IMS transactions or as high performance DBATs can hold tablespace locks across many transactions.
In the next article, I’ll tackle the four isolation levels, RR, RS, CS and UR in preparation for the following article on data anomalies.
Struggling with Db2 Locking?
We’ve helped countless teams overcome Db2 locking challenges. Yours could be next. Contact us.
Footnotes
1 Some applications require row-level locking to avoid contention, and some tablespace design options such as MEMBER CLUSTER with APPEND also require row-level locking (in the MEMBER CLUSTER case, to avoid exponential growth in the tablespace size resulting from massively parallel insert processing). LOCKSIZE ROW can impact performance as it increases the data sharing overhead.
2 This is known as autocommit, which is supported as a connection property for distributed clients using the IBM Data Server Driver. Autocommit is rarely used for update applications, but often used for read-only applications. A very unusual application could, in theory, issue an explicit COMMIT after every call, but I have never seen this in practice.
3 If autocommit is used for a business process that includes multiple update statements (INSERT, UPDATE, DELETE), then the business process needs to record every update SQL call it makes in an application log. This log will be needed for backout, restart and recovery to ensure the data is consistent from the business process point of view. All that’s needed for guaranteed data corruption after a subsystem or transaction failure is for the failure to occur between an SQL call and the update to the transaction log that records the update SQL event.
Db2 for z/OS-locking for Application Developers eBook
Gareth's eBook focuses on the role of the application programmer in collaborating with the locking mechanisms provided by Db2 to ensure data integrity.